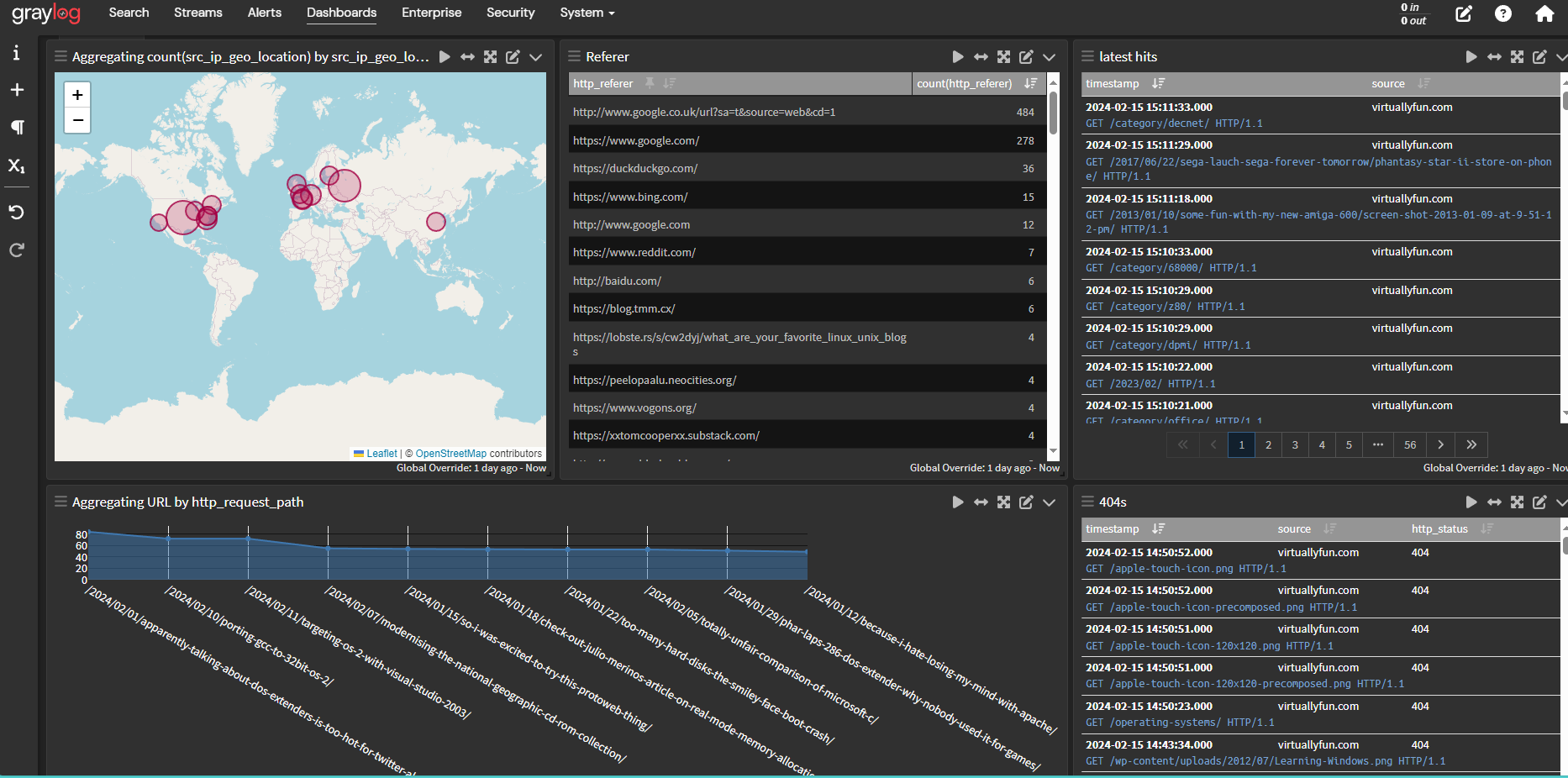
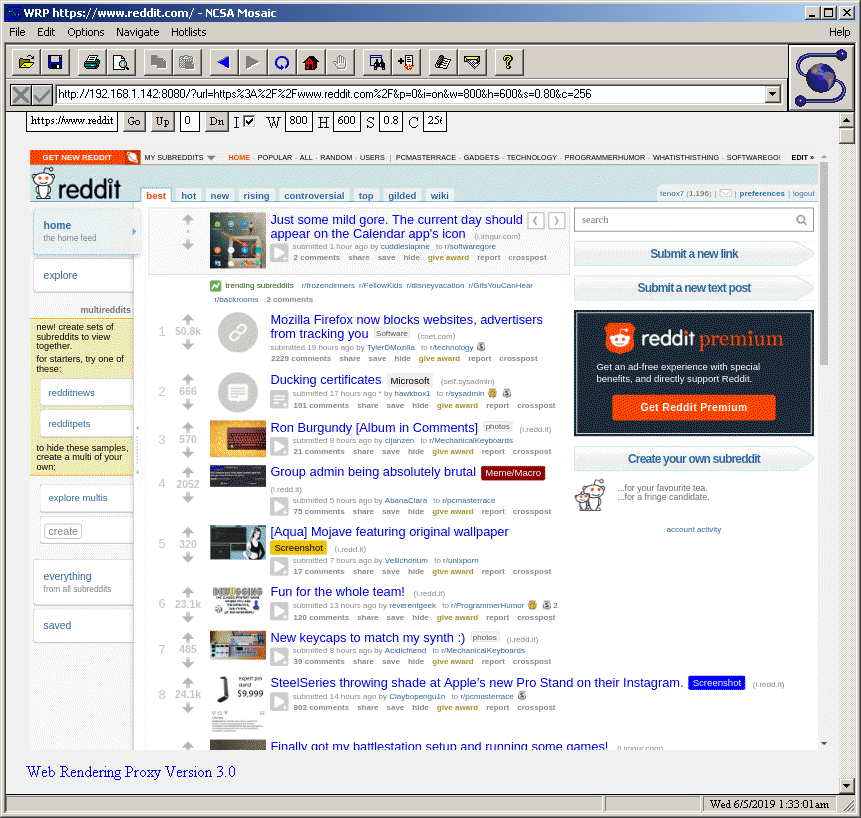
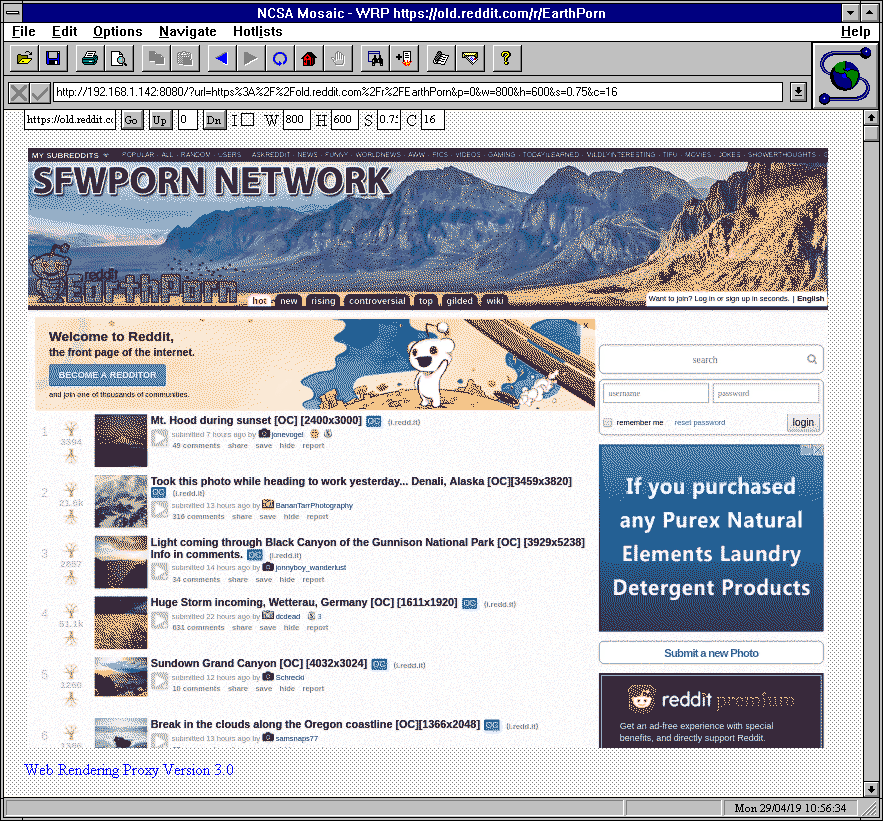
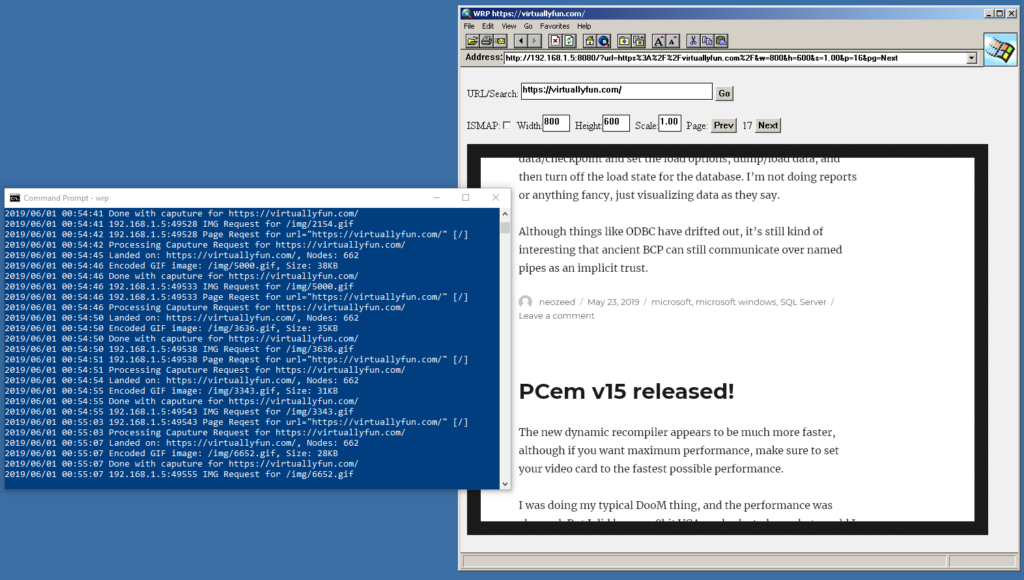
I saw this post from Action Retro over on twitter, and it just reminds me why we can’t have nice things on the internet. Some jerk is always going to destroy stuff, simply because it takes effort to create, while tearing down things only shows impotent rate.
FROGFIND UPDATE: Someone has been hammering the site with a scraper using rotating proxies that I can’t block. It’s pegging my server CPU at 100%. This has caused a service interruption. Working on solutions :'(
So annoying!
However, the source to Frog Find is available on github, so why not self-host a copy?
Since I’m using WordPress (not even touching that crazy WP drama!) I’ve already got a Linux machine running PHP/Apache (good olde LAMP!) so I thought this would be simple as, make a new virtual server, git clone the repo, and add a new entry to the olde DNS & Haproxy servers, and I’d be ready to go live!
[Tue Nov 19 11:35:50.601570 2024] [php:warn] [pid 25997:tid 25997] [client 127.0.0.1:49854] PHP Warning: require_once(vendor/autoload.php): Failed to open stream: No such file or directory in /srv/www/FrogFind/index.php on line 2Well, that was disappointing.
Looking at the repo there is this composer.json, so obviously it’s got something to do with that.
Looking around there is an incredible amount of information for installing & using it in your projects, but I don’t know why I struggled to find out how to actually use/deploy it. But it’s super simple, and of course it just needs you to curl & run stuff, which of course will never be used as a vector to spread malware. Never.
Installing composer into the local directory is simple as:
sudo curl -sS https://getcomposer.org/installer | phpAnd next, just run it with the following flags:
./composer.phar update --no-devAnd that’s it! It’ll get everything needed, and now hitting the site:
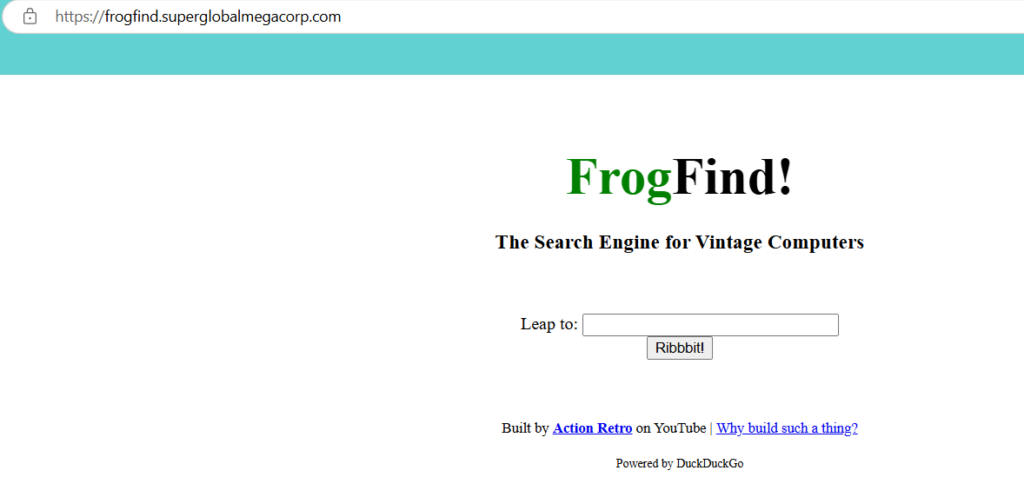
Just like that!
Since mine sits behind Cloudflare it locks out old browsers. I wonder about modifying some proxy to use 2 SSL’s to support ancient SSL, and ‘modern’ to proxy stuff, although it sure wouldn’t load new pages, but it could gate to services like a Frog Find on a service like Cloud Flare and modern crypto.
I’d encourage people to run locally hosted on their own LANs a copy of FrogFind. At least that way you won’t be interrupted by jerks.