
A while back I had made a small post about getting Graylog running on Windows. It was fun, as it’s just JAVA so you know it should be portable, and other than some weird disk access thing it does seem to run fine.
Of course, the next step is to create a dashboard to replace what I used on wp-statistics, as it was crashing taking up 100% of my CPU, and exceeding PHP’s 12GB of RAM per process limit. You know things are messed up when I’m replacing you with not one, but 2 Java apps! (Graylog & Opensearch).
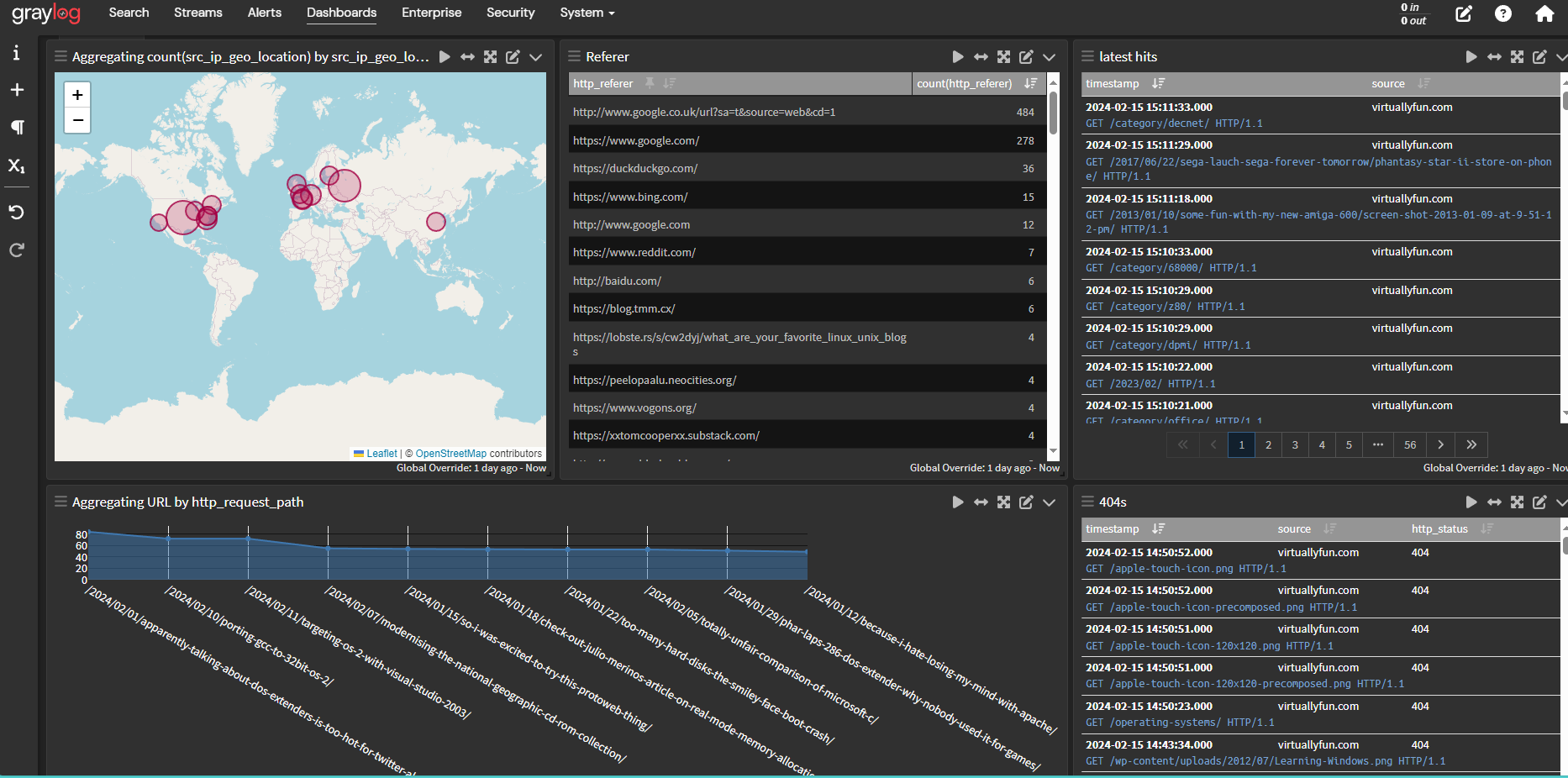
It’s by no means perfect, but the guide How to se -up graylog geoip configuration, is all around great to have. The rest of it is me learning how to do aggregate searches, and simple lists, to see latest hits, 404’s and count the pages and build a graph.
Again, this is all good, now for the real question, how to get this onto the Internet?!
The firs thing to do is enable cors.. It’s for being on the internet!
http_enable_cors = trueNext enable the external URI name
http_external_uri = https://dash.board.com/And now the changes I had to make in my haproxy config
frontend http-in
acl host_graylog hdr(host) -i dash.board.com
http-request set-uri %[path,regsub(/api/api,/api)] if host_graylog
use_backend graylog if host_graylog
backend graylog
option forwardfor
http-request add-header X-Forwarded-Host %[req.hdr(host)]
acl bad_ct path_end .js
http-response set-header Content-Type application/javascript if bad_ct
http-request set-header X-Graylog-Server-URL http://192.168.33.5:9000
server graylog 192.168.23.33:9000 maxconn 20 checkI kind of wish I saved the logs while going crazy but YES for some reason it’ll try to reference itself as /api/api. I don’t know why, so I had to do some uri regex to fix that. Neat!
Next for some reason Graylog responds that all .js (javascript) files are actually text. Chrome doesn’t allow that to work, so yes you need to set the content type header to “application/javascript” for Chrome to be happy.
I had wasted over an hour with this and couldn’t get it working. So, I walked away for a few hours, and it suddenly was working. I think Cloudflare was doing some caching against it.
This is probably too terse to be really useful, and I lost all the pages I was reading about setting stuff in haproxy as I was doing that incognito. Oops. I picked this config out of fragments from five other people’s stuff. There is other considerations to host it on a subdirectory of a public site, but I just wanted to K.I.S.S.
> I think Cloudflare was doing some caching against it.
So: could you please stop cloudflare stop “protecting” your rss feed?
I can understand – it looks like bot traffic but on the other hand this is the point of rss!
I do read and enjoy jour blog mostly via rss, but this stopped working now. Sad!
I was getting over a million hits a day to the rss, as someone was clearly broken/abusing it.
I’d put an 8 hour cache on the rss as I didn’t imagine I updated that much, but it’s really hard to tell if it’s broken, as nobody gives any contact information or any chance to see where/how/why. Someone else was hitting it too often, which was forcing a bot challenge. I’ve removed the limits for now, hoping someone else doesn’t abuse it so bad.