
For those who don’t know Graylog is a neat little event logging aggregate & search utility. Of course when I say ‘little’ its kinda on the massive size. It’s one of them new age web two-point-oh things, that of course has a few interesting dependencies.
- MongoDB
- OpenSearch
While I was looking at doing a deployment elsewhere, I went to get the latest versions directly from the vendors instead of relying on apt/yum/whatever. And much to my surprise, both Mongo & OpenSearch both have native Win64 versions! What a great time! Of course these will change, but for now
- mongodb-windows-x86_64-6.0.12-signed.msi
- opensearch-2.11.0-windows-x64.zip
- graylog-5.2.1-linux-x64.tgz
I’ve stashed a copy over on archive.org if anyone is insane enough to try this. One thing as of Graylog 5.xx is that it does say to stick with a MongoDB v6. So that’s what I did.
MongoDB
One thing to keep in mind is that the MongoDB is used for the configuration of the cluster, as Graylog is usually configured in a HA cluster, but there doesn’t need to be such an emphasis on the MongoDB as the size of the database isn’t so massive.
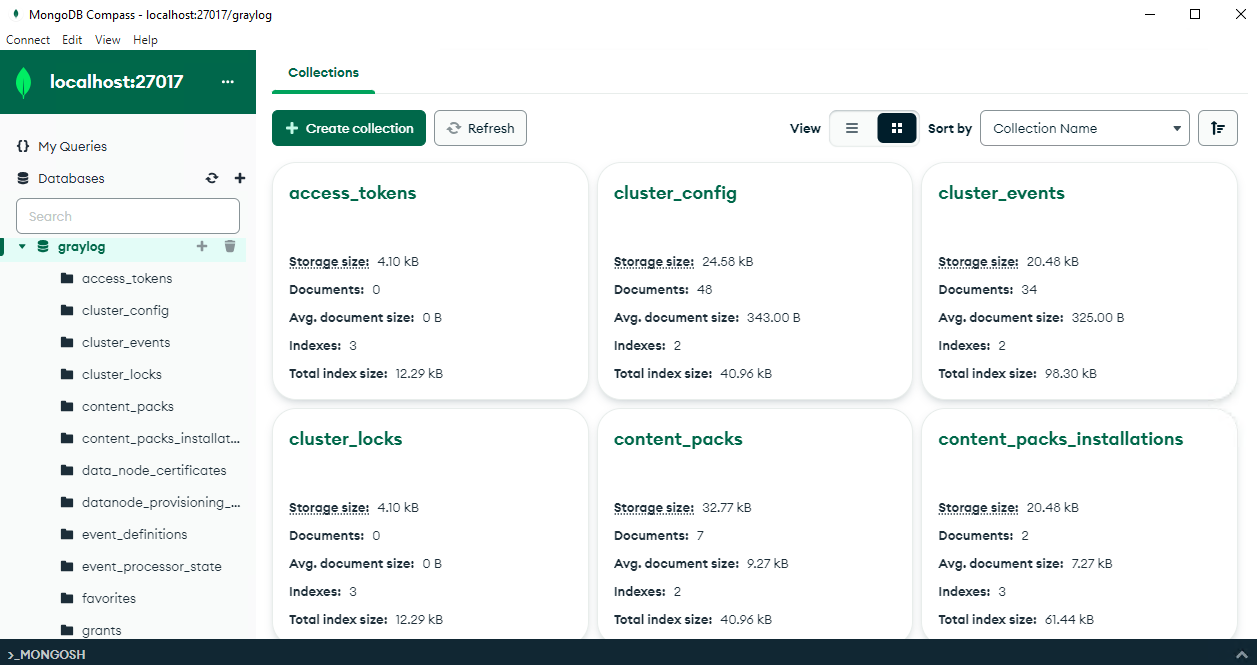
MongDB has a nice UI Compass, for exploring stuff. Although browsing around you’ll see it really is just system config stuff. So you won’t be needing some 100GB array for this stuff, more so VM’s for clustering it out if you want to go all high availability.
There isn’t much to say about the MongoDB install, just set it to a drive that you want.
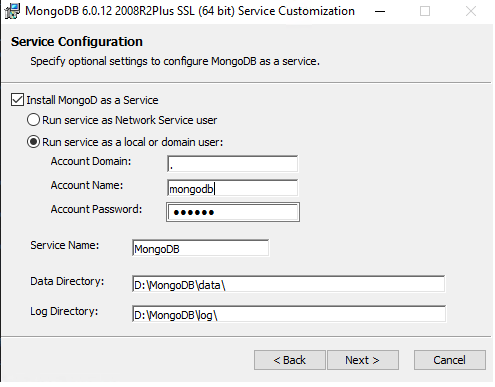
Of course set it up as a service, make the user if needed/desired (I did!). I went one step further and compressed the data directory since it’s on NTFS. I don’t think it mattered too much, its been a few days and it’s only 300MB give or take. The graylog dataset is very tiny as mentioned it’s just the configuration, so it wont be that much.
After the install is done, start the service, and you can then launch Compass, and you should be able to connect to your local database. And that’s it!
OpenSearch
OpenSearch is where all the ‘magic’ happens, where the data gets written, along with where your searches through the logs run. If you want to emphasis something, this is it.
OpenSearch didn’t have an install program, rather just a batch file to run and start it. There is a opensearch-service.bat file to install the service.
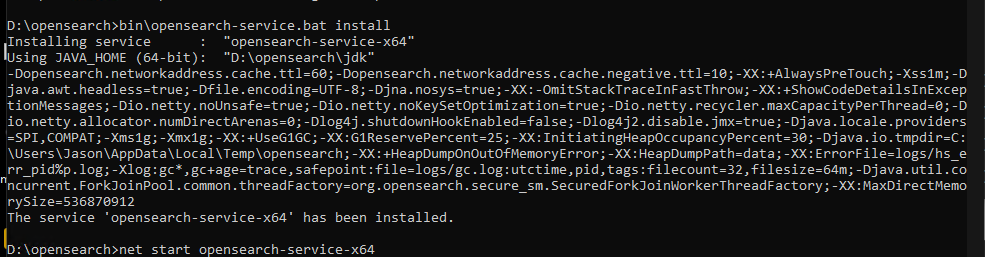
There are a few config changes I had to make:
cluster.name: graylog
http.port: 9200
plugins.security.disabled: trueAfter those changes to config\opensearch.yml you can install and run the service. You can then hit the service via http as http://127.0.0.1:9200 and you should get something similar to this.
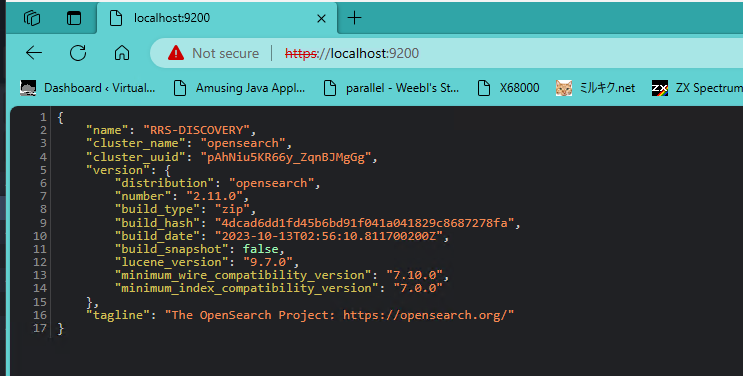
Graylog
As you may have seen from the downloads there is no Windows version of Graylog available for download. HOWEVER it’s a JAVA app. So other than one weird Unixisim of where to keep the config file, it’s just a java thing.
I did need a Linux install to set the required passwords. Although for this sake I used the admin/admin for maximum security, so you can always just work this diff into the server.conf file.
--- graylog.conf.example 2023-11-15 09:05:28.000000000 +0000
+++ server.conf 2023-11-30 21:53:13.580405300 +0000
@@ -54,10 +54,10 @@
# Generate one by using for example: pwgen -N 1 -s 96
# ATTENTION: This value must be the same on all Graylog nodes in the cluster.
# Changing this value after installation will render all user sessions and encrypted values in the database invalid. (e.g. encrypted access tokens)
-password_secret =
+password_secret = ihEUzuJNJOOIVYaNB29ZHZimi438NxKKzSys5UH6O9CoE7jfsrygCbuzzLzkK6hk0xdDb6e8wyAmTNhD7g9JMNZHXr1q40Ps
# The default root user is named 'admin'
-#root_username = admin
+root_username = admin
# You MUST specify a hash password for the root user (which you only need to initially set up the
# system and in case you lose connectivity to your authentication backend)
@@ -65,7 +65,7 @@
# modify it in this file.
# Create one by using for example: echo -n yourpassword | shasum -a 256
# and put the resulting hash value into the following line
-root_password_sha2 =
+root_password_sha2 = 8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
# The email address of the root user.
# Default is empty
@@ -102,7 +102,7 @@
# If the port is omitted, Graylog will use port 9000 by default.
#
# Default: 127.0.0.1:9000
-#http_bind_address = 127.0.0.1:9000
+http_bind_address = 192.168.1.5:9000
#http_bind_address = [2001:db8::1]:9000
#### HTTP publish URI
@@ -192,6 +192,7 @@
#
# Default: http://127.0.0.1:9200
#elasticsearch_hosts = http://node1:9200,http://user:password@node2:19200
+elasticsearch_hosts = http://127.0.0.1:9200
# Maximum number of attempts to connect to elasticsearch on boot for the version probe.
#
@@ -489,7 +490,9 @@
#auto_restart_inputs = true
# Enable the message journal.
-message_journal_enabled = true
+# message_journal_enabled = true
+# https://github.com/Graylog2/graylog2-server/issues/12949#issuecomment-1219146839
+message_journal_enabled = false
# The directory which will be used to store the message journal. The directory must be exclusively used by Graylog and
# must not contain any other files than the ones created by Graylog itself.
There is a few weird things in this config, The first one being the bind address to the external NIC, the elasticsearch_hosts being set to http as we ended up removing the SSL as Graylog didn’t like the self signed certs. However, since it’s all loopback traffic on the same machine, it does seem a bit silly to be encrypting to yourself. The other weird gotcha was message_journal_enabled, which fails after a few hours on both WSLv1 & a Win64 native. I don’t know why but it’s a common problem on non EXT2FS based filesystems, and sadly the solution everywhere is just turn it off.
Starting Graylog is kind of easy once you work out the CLI from the Linux script, using the JVM from OpenSearch. Take note of the log4j2, the one from that big deal vulnerability in all the fancy web apps.
\opensearch\jdk\bin\java.exe -Dlog4j2.formatMsgNoLookups=true ^
-Djdk.tls.acknowledgeCloseNotify=true ^
-Xms1g -Xmx1g -XX:+UseG1GC ^
-XX:-OmitStackTraceInFastThrow ^
-jar graylog.jar server -f server.conf ^
-p graylog.pid I run this manually. With any luck you’ll see it connect to the databases and go live!
2023-12-02 15:37:37,749 INFO : org.mongodb.driver.cluster - Monitor thread successfully connected to server with description ServerDescription{address=localhost:27017, type=STANDALONE, state=CONNECTED, ok=true, minWireVersion=0, maxWireVersion=17, maxDocumentSize=16777216, logicalSessionTimeoutMinutes=30, roundTripTimeNanos=29209200}
2023-12-02 15:37:45,518 INFO : org.graylog2.storage.providers.ElasticsearchVersionProvider - Elasticsearch cluster is running OpenSearch:2.11.0
2023-12-02 15:37:48,593 INFO : org.graylog2.bootstrap.ServerBootstrap - Graylog server 5.2.1+4337e8c starting up
2023-12-02 15:37:48,594 INFO : org.graylog2.bootstrap.ServerBootstrap - JRE: Eclipse Adoptium 17.0.8 on Windows 10 10.0
2023-12-02 15:37:48,594 INFO : org.graylog2.bootstrap.ServerBootstrap - Deployment: unknown
2023-12-02 15:37:48,595 INFO : org.graylog2.bootstrap.ServerBootstrap - OS: Windows 10
2023-12-02 15:37:48,595 INFO : org.graylog2.bootstrap.ServerBootstrap - Arch: amd64
2023-12-02 15:37:48,694 INFO : org.graylog2.bootstrap.ServerBootstrap - Running 67 migrations...And from there you ought to be ready to run!?

I don’t want to re-install but it should offer a chance to setup the self signed certificate maintenance, and then you are dumped into the system. One nice thing on Windows is you can create UDP 514 Syslog captures with no silly port reflection. Although you could run them in WSLv1 or VM’s entirely by having all of this as native Win64 makes the memory and performance overhead much lower.
Apache
I use graylog to capture my blog’s Apache stats.
In my apache site config under the logging I added this:
LogFormat "{ \"version\": \"1.1\", \"host\": \"%V\", \"short_message\": \"%r\", \"timestamp\": %{%s}t, \"level\": 6, \"_user_agent\": \"%{User-Agent}i\", \"_source_ip\": \"%a\", \"_duration_usec\": %D, \"_duration_sec\": %T, \"_request_size_byte\": %O, \"_http_status_orig\": %s, \"_http_status\": %>s, \"_http_request_path\": \"%U\", \"_http_request\": \"%U%q\", \"_http_method\": \"%m\", \"_http_referer\": \"%{Referer}i\", \"_from_apache\": \"true\" }" graylog_access
CustomLog "|/usr/bin/nc -u 127.0.0.1 12201" graylog_accessOf course, keeping in mind that I do front with Cloudflare, so the source_ip will probably be different for you. Netcat does the job nicely, and since it’s WSLv1 all the TCP/IP is unified so it can intermix just fine.
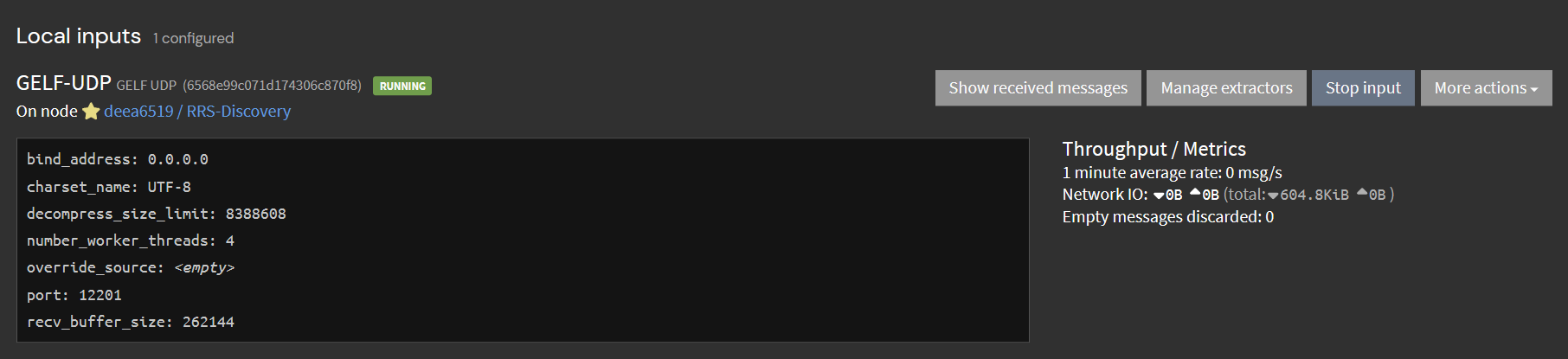
Setting up the input as the stock boring GELF-UDP was a snap, and in no time apache is now sending the access log to Graylog in GELF, and all is well. It’s great!
I know that my setup is.. far from normal, and I do have quite a few VM’s but this old machine is more than capable of hosting this site, a few others, along with the overhead of Graylog.
Would I recommend this in production? I have to think that since so much of this is now available on native Win64 that at least 2/3rd of it is capable. I’m not to worried about the potential of Graylog dropping data if the host is interrupted as everything else is here. I can understand if other people have very different thoughts on that. Not everyone wants to run a 90’s datacentre on some old machine tucked under the Christmas Tree, but I guess I’m weird enough to do so.
I suppose the where to go from here, is to get everything else logging to graylog so I can build dashboards, and reports. But that sounds like a lot of work, and at the moment I think this is a good enough place to stop. I should add that it’s been running for nearly 2 days now, so that’s good enough for prime time right? RIGHT?!