Introduction

Long before websites, during the dark ages of the BBS, on the internet there was (well it’s still there!) a distributed messaging system called usenet. Â There are countless topics on just about everything that was full of all kinds of incredible conversations. Â Before the walled gardens, and the ease of running individual bulletin boards, the internet had prided itself on having one big global distributed messaging system. Â It was a big system, and one thing that was always taken for granted was that it was too big to save, and that whatever you put out there would probably be erased as all sites had a finite amount of very expensive disk space, and they would only keep recent articles.
But it turns out that in the University of Toronto, in the zoology department they had a tape budget, and were in fact archiving everything they could.  In all they had amassed 141 tapes spanning from February 1981 (though these are not Usenet posts, just internal netnews University stuff) all the way up to about midnight of July 01, 1991!
While the archive was made available to a few people in 2001, it was made generally available in 2009, and then in 2011 on archive.org where I downloaded a copy of it. Â There is some interesting backstory over on Dogcow land, as it took quite a bit of effort to get the data from the tapes, and then slowly released out into the wild.
As mentioned on the archive.org site:
This is a collection of .TGZ files of very early USENET posted data provided by a number of driven and brave individuals, including David Wiseman, Henry Spencer, Lance Bailey, Bruce Jones, Bob Webber, Brewster Kahle, and Sue Thielen.
OK, so back a few months ago, I had setup AltaVista personal desktop search along with the UTZOO usenet archive for the purpose of using something more sophisticated than grep, but maintaining that legacy/retro feel us using outdated technology. Â To recap the first challenge is that the desktop search product, is only meant to be used from the desktop of a Windows 98/NT 4.0 workstation. Â It uses a super ancient version of JAVA as the webserver, and they chose to bind it to 127.0.0.1:6688 . Â So the first thing to get around that was to build a stunnel tunnel allowing me to effectively connect to the webserver remotely. Â And since the server assumes it’s locally I had to use Apache with mod_rewrite to setup some simple regex expressions to massage the pages into something that would be usable from a non local machine.
So with that word salad up, let’s have a brief picture!
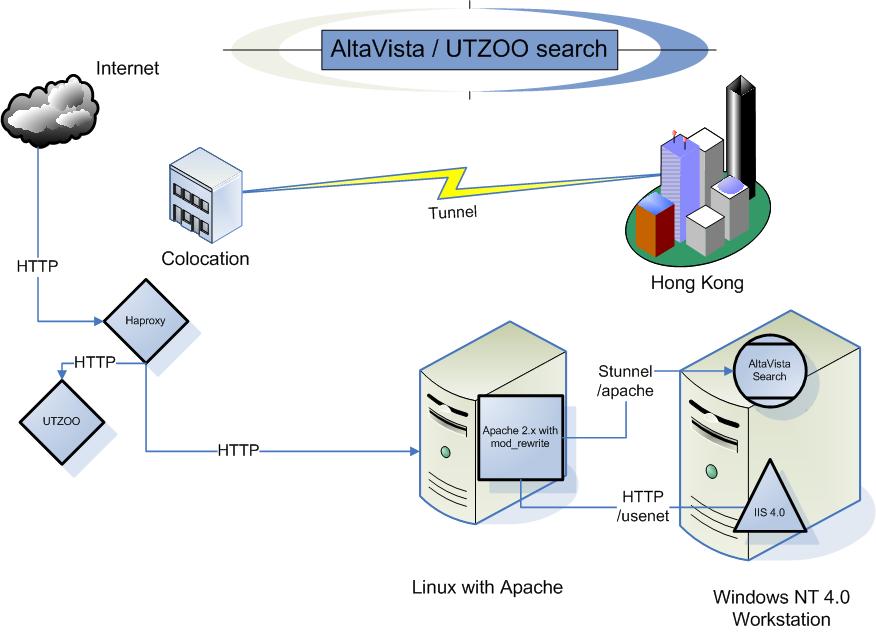
Flow diagram
Stepping it up
On my ‘general’ hosting machine, I use haproxy to reverse proxy out multiple sites out the single address. Â This is a super simple solution that allows me to have all kinds of different backends using various hosting platforms, such as Apache 1.3 on Windows NT 3.1. Â So for this to work I just needed to create an altavista.superglobalmegacorp.com DNS record, and then the following in the haproxy config:
frontend named-hosts
bind 172.86.179.14:80
acl is_altavista hdr_end(host) -i altavista.superglobalmegacorp.com
use_backend altavista if is_altavista
backend altavista
balance roundrobin
option httpclose
option forwardfor
server debian8 10.0.0.18:80 check maxconn 10
So as you can see it’s really simple it looks for the string ‘altavista.superglobalmegacorp.com’ in the host header, and then sends it to the backend that has a single web server, in this case a lone Debian server, aptly named debian8 that throttles after 10 concurrent connections.
The next thing to do was generate a SSL self signed cert, which wasn’t too hard. Â The stunnel installer has a profile ready to go, so it was only a matter of finding a version of OpenSSL that’ll run on NT 4. Â As this isn’t public encryption I really don’t care about it using crap certs.
On the Debian server is where all the regex magic, is along with the stunnel client to connect to the NT 4.0 Workstation.
client = yes
debug = 0
cert = /etc/stunnel/stunnel.pem
[altavista]
accept = 127.0.0.1:8080
connect = 10.0.0.19:8443
Likewise on NT stunnel will need a config like this:
cert = c:\stunnel\stunnel.pem
; Some performance tunings
socket = l:TCP_NODELAY=1
socket = r:TCP_NODELAY=1
; Some debugging stuff useful for troubleshooting
debug = 0
output = c:\stunnel\stunnel.log.txt
[altavista]
accept = 8443
connect = 127.0.0.1:6688
With the ability for the Debian box to talk to the AltaVista web server, it was now time to configure Apache. Â This is the most involved part, as the html formatting by AltaVista personal search is hard coded into the java binary. Â However thanks to mod_rewrite we can modify the page on the fly! Â So the first thing is that I setup to virtual directories, the first one /altavista maps to the search engine, and then I added /usenet which then talks to IIS 4.0 on the Windows NT 4.0 workstation, which is just allowing read & browse to the usenet files that will need to be indexed.
#This part connect to a stunnel connection to the Altavista server
ProxyPass “/altavista” “http://localhost:8080”
ProxyPassReverse “/altavista” “http://localhost:8080”
#This connects to IIS 4.0 on the NT 4.0 machine
ProxyPass “/usenet” “http://10.0.0.19/usenet”
ProxyPassReverse “/usenet” “http://10.0.0.19/usenet”
ProxyRequests Off
RewriteEngine On
Because we mounted it on a sub directory we need to redirect the root to /altavista so I simply add:
#Redirect the root to the /altavista path.
#
RedirectMatch 301 ^/$ /altavista
To get the images to work, along with fixing the 127.0.0.1 hardcoding, Â I copied them from the NT workstation onto the Apache server, then added this regex statement:
#clean up urls
Substitute “s|Copyright 1997|Copyright 2017|n”
Substitute “s|127.0.0.1:6688|altavista.superglobalmegacorp.com/altavista|n”
Substitute “s|file:///c:\Program Files\DIGITAL\AltaVista Search\My Computer\images\|/images/|n”
And now the site is starting to work. Â The most involved regex is to change the links from local text files, into a path to point to the usenet shares. Â This changes the text for u:\usenet\a333\comp\33.txt into a workable URL.
Substitute “s|>u:\\\\usenet.([a-z]{1,}[0-9]{3,})\\\([0-9a-z\+\-]{1,})\\\([0-9]{1,})|—><a href=\”http://utzoo.superglobalmegacorp.com/usenet/$1/$2/$3.txt\”>[$2\] Click for article|“
Naturally there is a LOT of these type of statements to match various depths, and pattern types as there is A news, B news and C news archives, plus scavenged bits.
Additionally I disabled a bunch of URL’s that would either try to alter the way the engine works, or allow the search location to change, just giving you empty results, along with altering some of the branding, as digital.com doesn’t exist anymore, and various tweeks. Â The finished config file for Apache is here.
Now with that in place, I can hit my personal AltaVista search. Â The next insane thing was to rename all the files from the UTZOO dump adding a .txt extension, and then re-encoding them in MS-DOS CR/LF format. Â I found using ‘find -type f’ to find files, and then a simple exec to rename them into a .txt extension. Â Then it was only a matter of using ZIP to compress the archives, and then transferring them to Windows NT, and running UNZIP on them with the -a flag to convert them into CR/LF ASCII files on Windows. Â This took a tremendous amount of time as there are about 2.1Â million files in the archive.
Now with the files on Windows, now I had to run the indexer.
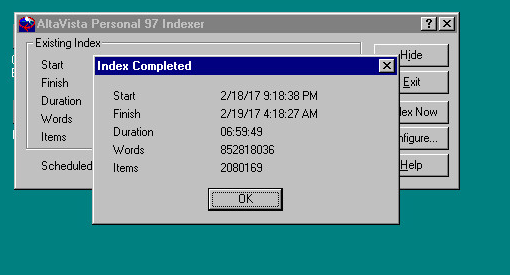
Indexed in under 7 hours!
While I had originally had an IIS 4.0 instance on the same NT 4.0 Workstation serving up the result files, I thought it may make more sense to just serve them from the UTZOO mirror server I have in the same collocation so it’d be much faster, so that way only the queries are relying on servers in Hong Kong, instead of being 100% located in the United States.
So here we go, my search portal for all that ancient usenet goodness:
altavista.superglobalmegacorp.com
If you are hoping for the wealth of knowledge to be gained from people posting on usenet from 1981 to 1991 then this is your ticket. Â Keep in mind that usenet being usenet, there is discussions on everyone and everything, and like all other forums before you know it it’ll end with calling people Hitler, and how the Amiga is the greatest computer ever (well it was!). Â A tip when searching by year, is that people commonly wrote the year as 2 digits. Â However when looking for numbers like, say Battletech 3025, it will pull up files named 3025.txt. Â To prevent this just add -3025.txt to stop names like 3025.txt, or if you want to find out about the movie Bladerunner from 1982, try searching for bladrunner 82 -82.txt +review +movie. Â If you have any questions, there is of course the manual with a guid on how to search.
While the story of AltaVista is somewhat interesting, but much like how Digitial screwed up the Alpha market by trying to hoard high end designs, they also didn’t set the search people free to focus on search. Â And the intranet stuff was crazy expensive, look at this ad from 1996Â which translate to a minimum of $10,000 USD a year to run a single search engine! Â But as we all know, the distributed model of google won search and AltaVista never had a chance as it was caught up in the Compaq/HP mess then spun out to be quickly absorbed by Yahoo.
Meanwhile it appears the original owners of altavista.com, AltaVista Technology, Inc. of California, are actually still in business.  If anyone cares I’ll put the installation files, and some of the config’s in this directory.