Seriously, the sad thing is that they wasted all their time, and bandwidth. The good thing is that PHP7 is far better at this, than PHP5. I know it’s not hipster neaveaux but PHP7 is really awesome stuff.
I didn’t wake up to a million messages about being down, rather a look at what was going on showed me this:

Obviously something is up.
I checked Cloudflare:
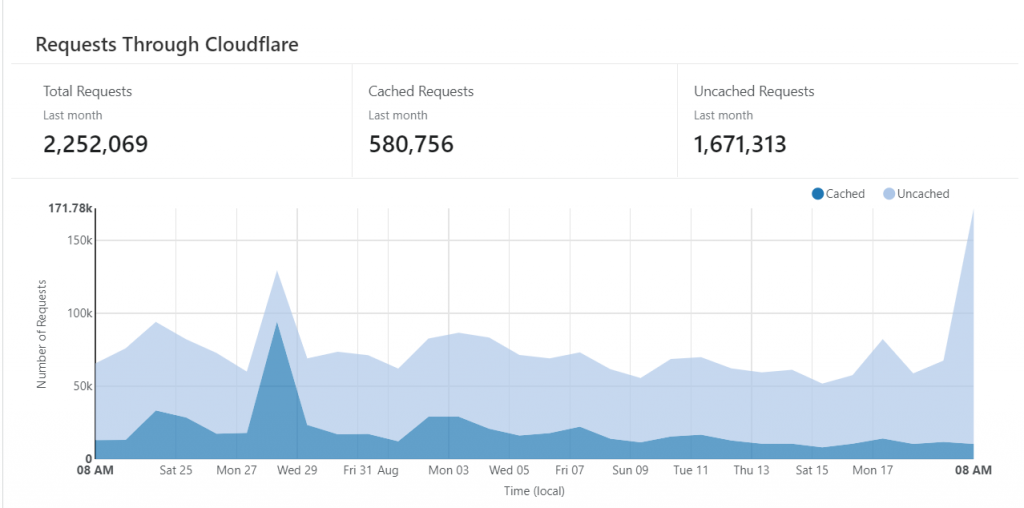
All those hits, and no change in user traffic. So I’m not popular.
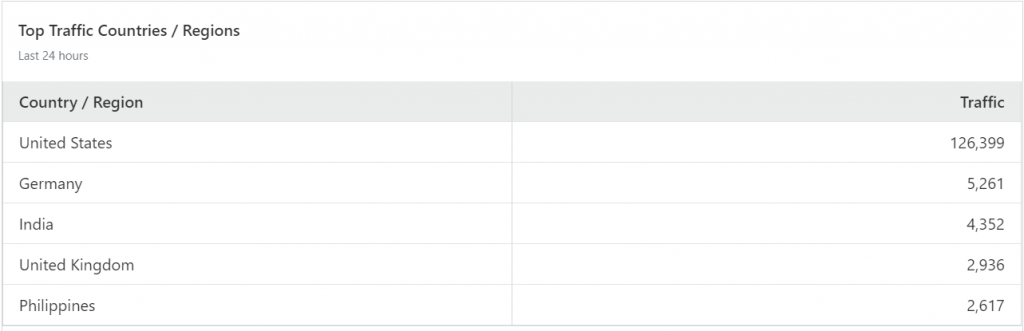
And it’s all from the United States. Going back to WordPress I can see it’s mostly from one user!

A look through the 30MB log, and it’s a broken site scrape
174.127.114.00 - - [20/Aug/2020:20:43:39 -0400] "GET /wordpress/category/windows-nt-4-0/%5C'https://virtuallyfun.com/wordpress/2020/03/17/philip-pembertons-3b1-emulator-moved/%5C' HTTP/1.1" 301 - "https://virtuallyfun.com/wordpress/category/windows-nt-4-0/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
174.127.114.00 - - [20/Aug/2020:20:43:40 -0400] "GET /wordpress/category/windows-nt-4-0/%5Chttps:/virtuallyfun.com/wordpress/2020/03/17/philip-pembertons-3b1-emulator-moved/%5C HTTP/1.1" 404 32750 "https://virtuallyfun.com/wordpress/category/windows-nt-4-0/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
174.127.114.00 - - [20/Aug/2020:20:43:40 -0400] "GET /wordpress/category/windows-nt-4-0/%5C'https://virtuallyfun.com/wordpress/2020/03/12/the-price-of-commodore-64s-is-getting-out-of-control/%5C' HTTP/1.1" 301 - "https://virtuallyfun.com/wordpress/category/windows-nt-4-0/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
174.127.114.00 - - [20/Aug/2020:20:43:41 -0400] "GET /wordpress/category/windows-nt-4-0/%5Chttps:/virtuallyfun.com/wordpress/2020/03/12/the-price-of-commodore-64s-is-getting-out-of-control/%5C HTTP/1.1" 404 32752 "https://virtuallyfun.com/wordpress/category/windows-nt-4-0/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
174.127.114.00 - - [20/Aug/2020:20:43:41 -0400] "GET /wordpress/category/windows-nt-4-0/%5C'https://virtuallyfun.com/wordpress/2020/03/08/thanks-to-lgr-i-just-found-out-about-simcity-for-palm-pilots-was-a-thing/%5C' HTTP/1.1" 301 - "https://virtuallyfun.com/wordpress/category/windows-nt-4-0/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
174.127.114.00 - - [20/Aug/2020:20:43:42 -0400] "GET /wordpress/category/windows-nt-4-0/%5Chttps:/virtuallyfun.com/wordpress/2020/03/08/thanks-to-lgr-i-just-found-out-about-simcity-for-palm-pilots-was-a-thing/%5C HTTP/1.1" 404 32751 "https://virtuallyfun.com/wordpress/category/windows-nt-4-0/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"This is just terrible you are quoting the link to the link, having slashes going every which way. What the heck!? Don’t be a jerk, pace the thing, why are you trying to DOS it? While my hosting is clearly not robust, why can’t you wait a few seconds between each query? Also look at the output and URL’s it’s sending it’ll never work!
Oh and speaking of WTF:
[Sat Aug 15 02:54:16.376342 2020] [:error] [pid 2176618:tid 46981722752768] [client 5.188.84.35:0] [client 5.188.84.35] ModSecurity: Access denied with code 403 (phase 2). Match of "rbl nxdomain.v2.rbl.imunify.com." against "TX:rbl_ip" required. [file "/etc/apache2/conf.d/modsec_vendor_configs/imunify360-full-apache/001_i360_1_generic.conf"] [line "18"] [id "77140164"] [msg "Infectors: PHP Injection Low value||MVN:TX:rbl_ip||T:APACHE||MV:02-54.5.188.84.35||PC:74973||SC:/home/virtuall/public_html/wp-comments-post.php"] [severity "WARNING"] [maturity "1"] [accuracy "7"] [tag "service_o"] [tag "service_i360"] [hostname "virtuallyfun.com"] [uri "/wp-comments-post.php"] [unique_id "XzeGmAmHABK5lhefvTgiWQAAAQI"], referer: https://virtuallyfun.com/wordpress/2019/07/25/c-beams-glitter-in-the-dark-near-the-tannhauser-gate/#comment-217724/<br>
[Sat Aug 15 00:59:09.378579 2020] [:error] [pid 2121712:tid 46981729056512] [client 5.188.84.25:0] [client 5.188.84.25] ModSecurity: Access denied with code 403 (phase 2). Match of "rbl nxdomain.v2.rbl.imunify.com." against "TX:rbl_ip" required. [file "/etc/apache2/conf.d/modsec_vendor_configs/imunify360-full-apache/001_i360_1_generic.conf"] [line "18"] [id "77140164"] [msg "Infectors: PHP Injection Low value||MVN:TX:rbl_ip||T:APACHE||MV:00-59.5.188.84.25||PC:71624||SC:/home/virtuall/public_html/wp-comments-post.php"] [severity "WARNING"] [maturity "1"] [accuracy "7"] [tag "service_o"] [tag "service_i360"] [hostname "virtuallyfun.com"] [uri "/wp-comments-post.php"] [unique_id "XzdrnVSmjfAxcRCyCxt4rAAAAIU"], referer: https://virtuallyfun.com/wordpress/2019/07/25/c-beams-glitter-in-the-dark-near-the-tannhauser-gate/#comment-217724/There is no comment on that page. There never was. Look I know it sucks he’s dead, but there is nothing you or me can do about it.