(This is a guest post by Antoni Sawicki aka Tenox)
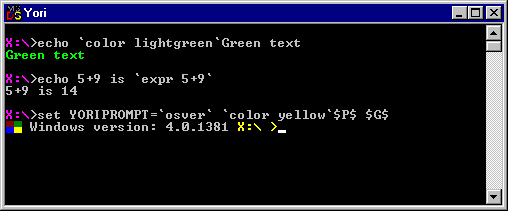
Today I have discovered Yori. So should you. No one can be told what Yori is, you need to take the red pill and see if for yourself.
Also more stuff from malxau.

(This is a guest post by Antoni Sawicki aka Tenox)
Today I have discovered Yori. So should you. No one can be told what Yori is, you need to take the red pill and see if for yourself.
Also more stuff from malxau.
(this is a guest post by Antoni Sawicki aka Tenox)
This is a lame duck, low effort post. If you already know it’s 🤦 obvious. However this question seem to be asked a lot on the intertubes. I was stupid and searched for it too. I hope this will help someone else, as there is no good readily available answer out there.
Problem: I want to have SNMP on my Comcast/Xfinity/AT&T router so I can monitor current bandwidth usage.
Research:
Nope or very hard / unsupported.
So is it possible at all? Yes, but with a separate device.
Comcast/Xfinity routers have so called “Bridge Mode” which essentially turns them in to a DOCSIS modem without the router / firewall / wifi access point. AT&T has a passthrough mode which works similarly.
Solution: Turn on Bridge/Passthrough Mode in your vanilla router and buy a WRT firmware router / access point. I got Linksys AC3200 for $99 on Amazon. Ssh to the router and run: opkg install snmpd. 🤦
Done.
This is an anonymous guest post. Disclaimer: Nothing in this post constitutes legal advice. The author is not a lawyer. Consult a legal professional for legal advice.
The UNIX® system is an old operating system, possibly older than many of the readers of this post. However, despite its age, it still has not been open sourced completely. In this post, I will try to detail which parts of which UNIX systems have not yet been open sourced. I will focus on the legal situation in Germany in particular, taking it representative of European law in general – albeit that is a stretch, knowing the diversity of European jurisdictions. Please note that familiarity with basic terms of copyright law is assumed.
The term “Ancient UNIX” refers to the versions of UNIX up to and including Seventh Edition UNIX (1979) including the 32V port to the VAX. Ancient UNIX was created at Bell Laboratories, a subsidiary of AT&T at the time. It was later transferred of the AT&T UNIX Support Group, then AT&T Information Systems and finally the AT&T subsidiary UNIX System Laboratories, Inc. (USL). The legal situation differs between the United States of America and Germany.
In a ruling as part of the UNIX System Laboratories, Inc. v. Berkeley Software Design, Inc. (USL v. BSDi) case, a U.S. court found that USL had no copyright to the Seventh Edition UNIX system and 32V – arguably, by extension, all earlier versions of Ancient UNIX as well – because USL/AT&T had failed to affix copyright notices and could not demonstrate a trade secret. Due to the obsessive tendency of U.S. courts to consider themselves bound to precedents (cf. the infamous Pierson v. Post case), it can be reasonably expected that this ruling would be honored and applied in subsequent cases. Thus under U.S. law, Ancient UNIX can be safely assumed to belong in the public domain.
The situation differs in Germany. Unlike the U.S., copyright never needed registration in order to exist. Computer programs are works in the sense of the German 1965 Act on Copyright and Related Rights (Copyright Act, henceforth CopyA) as per CopyA § 2(1) no. 1. Even prior to the amendment of CopyA § 2(1) to include computer programs, computer programs have been recognized as copyrightable works by the German Supreme Court (BGHZ 112, 264 Betriebssystem, no. 19); CopyA § 137d(1) rightly clarifies that. The copyright holder at 1979 would still have been USL via Bell Labs and AT&T. Copyright of computer programs is transferred to the employer upon creation under CopyA § 69(1).
Note that this does not affect expiry (Daniel Kaboth/Benjamin Spies, commentary on CopyA §§ 69a‒69g, in: Hartwig Ahlberg/Horst-Peter Götting (eds.), Urheberrecht: UrhG, KUG, VerlG, VGG, Kommentar, 4th ed., C. H. Beck, 2018, no. 16 ad CopyA § 69b; cf. Bundestag-Drucksache [BT-Drs.] 12/4022, p. 10). Expiry occurs 70 years after the death of the (co-)author that died most recently as per CopyA § 65(1) and 64; this has been the case since at least the 1960s, meaning there is no way for copyright to have expired already (old version, as per Bundesgesetzblatt Part I No. 51 of September 16, 1965, pp. 1273‒1294).
In Germany, private international law applies the so-called “Territorialitätsprinzip” for intellectual property rights. This means that the effect of an intellectual property right is limited to the territory of a state (Anne Lauber-Rönsberg, KollisionsR, in: Hartwig Ahlberg/Horst-Peter Götting (eds.), ibid., pp. 2241 et seqq., no. 4). Additionally, the “Schutzlandprinzip” applies; this means that protection of intellectual property follows the lex loci protectionis, i.e. the law of the country for which protection is sought (BGH GRUR 2015, 264 HiHotel II, no. 25; BGH GRUR 2003, 328 Sender Felsberg, no. 24), albeit this is criticized in parts of doctrine (Lauber-Rönsberg, ibid., no. 10). The “Schutzlandprinzip” requires that the existence of an intellectual property right be verified as well (BGH ZUM 2016, 522 Wagenfeld-Leuchte II, no. 19).
Thus, in Germany, copyright on Ancient UNIX is still alive and well. Who has it, though? A ruling by the U.S. Court of Appeals, Tenth Circuit, in the case of The SCO Group, Inc. v. Novell, Inc. (SCO v. Novell) in the U.S. made clear that Novell owns the rights to System V – thus presumably UNIX System III as well – and Ancient UNIX, though SCO acquired enough rights to develop UnixWare/OpenServer (Ruling 10-4122 [D.C. No. 2:04-CV-00139-TS], pp. 19 et seq.). Novell itself was purchased by the Attachmate Group, which was in turn acquired by the COBOL vendor Micro Focus. Therefore, the rights to SVRX and – outside the U.S. – are with Micro Focus right now. If all you care about is the U.S., you can stop reading about Ancient UNIX here.
So how does the Caldera license factor into all of this? For some context, the license was issued January 23, 2002 and covers Ancient UNIX (V1 through V7 including 32V), specifically excluding System III and System V. Caldera, Inc. was founded in 1994. The Santa Cruz Operation, Inc. sold its rights to UNIX to Caldera in 2001, renamed itself to Tarantella Inc. and Caldera renamed itself The SCO Group. Nemo plus iuris ad alium transferre potest quam ipse habet; no one can transfer more rights than he has. The question now becomes whether Caldera had the rights to issue the Caldera license.
I’ve noted it above but it needs restating: Foreign decisions are not necessarily accepted in Germany due to the “Territorialitätsprinzip” and “Schutzlandprinzip” – however, I will be citing a U.S. ruling for its assessment of the facts for the sake of simplicity. As per ruling 10-4122, “The district court found the parties intended for SCO to serve as Novell’s agent with respect to the old SVRX licenses and the only portion of the UNIX business transferred outright under the APA [asset purchase agreement] was the ability to exploit and further develop the newer UnixWare system. SCO was able to protect that business because it was able to copyright its own improvements to the system. The only reason to protect the earlier UNIX code would be to protect the existing SVRX licenses, and the court concluded Novell retained ultimate control over that portion of the business under the APA.” The relevant agreements consist of multiple pieces:
The APA dates September 19, 1995, from before the Caldera license. Caldera cannot possibly have acquired rights that The Santa Cruz Operation, Inc. itself never had. Furthermore, I’ve failed to find any mention of Ancient UNIX; all that is transferred is rights to SVRX. Overall, I believe that the U.S. courts’ assesment of the facts represents the situation accurately. Thus for all intents and purposes, UNIX up to and including System V remained with Novell/Attachmate/Micro Focus. Caldera therefore never had any rights to Ancient UNIX, which means it never had the rights to issue the Caldera license. The Caldera license is null and void – in the U.S. because the copyright has been lost due to formalities, everywhere else because Caldera never had the rights to issue it.
The first step to truly freeing UNIX would this be to get Micro Focus to re-issue the Caldera license for Ancient UNIX, ideally it would now also include System III and System V.
Another operating system near UNIX is of interest. The USL v. BSDi lawsuit includes two parties: USL, which we have seen above, and Berkeley Software Design, Inc. BSDi sold BSD/386 (later BSD/OS), which was a derivative of 4.4BSD. The software parts of the BSDi company were acquired by Wind River Systems, whereas the hardware parts went to iXsystems. Copyright is not disputed there, though Wind River Systems ceased selling BSD/OS products 15 years ago, in 2003. In addition, Wind River System let their trademark on BSD expire, though this is without consequence for copyright.
BSD/OS is notable in the sense that it powered much of early internet infrastructure. Traces of its legacy can still be found on Richard Stevens’ FAQ.
To truly make UNIX history free, BSD/OS would arguably also need to see a source code release. BSD/OS at least in its earliest releases under BSDi would ship with source code, though under a non-free license, far from BSD or even GPL licensing.
The fate of System V as a whole is difficult to determine. Various licenses have been granted to a number of vendors (Dell UNIX comes to mind; HP for HP-UX, IBM for AIX, SGI UNIX, etc.). Sun released OpenSolaris – notoriously, Oracle closed the source to Solaris again after its release –, which is a System V Release 4 descendant. However, this means nothing for the copyright or licensing status of System V itself. Presumably, the rights with System V still remain with Novell (now Micro Focus): SCO managed to sublicense rights to develop and sell UnixWare/OpenServer, themselves System V/III descendants, to unXis, Inc. (now known as Xinuos, Inc.), which implies that Xinuos is not the copyright holder of System V.
Obviously, to free UNIX, System V and its entire family of descendants would also need to be open sourced. However, I expect tremendous resistance on part of all the companies mentioned. As noted in the “Ancient UNIX” section, Micro Focus alone would probably be sufficient to release System V, though this would mean nothing for the other commercial System V derivatives.
The fate of Bell Labs would be a different one; it would go on to be purchased by Lucent, now part of Nokia. After commercial UNIX got separated out to USL, Research UNIX would continue to exist inside of Bell Labs. Research UNIX V8, V9 and V10 were not quite released by Alcatel-Lucent USA Inc. and Nokia in 2017.
However, this is merely a notice that the companies involved will not assert their copyrights only with respect to any non-commercial usage of the code. It is still not possible, over 30 years later, to freely use the V8 code.
In the U.S., Ancient UNIX is freely available. People located everywhere else, however, are unable to legally obtain UNIX code for any of the systems mentioned above. The exception being BSD/OS, assuming a purchase of a legitimate copy of the source code CD. This is deeply unsatisfying and I implore all involved companies to consider open sourcing (preferably under a BSD-style license) their code older than a decade, if nothing else, then at least for the sake of historical purposes. I would like to encourage everybody reading this to consider reaching out to Micro Focus and Wind River Systems about System V and BSD/OS, respectively. Perhaps the masses can change their minds.
A small note about patents: Some technologies used in newer iterations of the UNIX system (in particular the System V derivatives) may be encumbered with software patents. An open source license will not help against patent infringement claims. However, the patents on anything used in the historical operating systems will certainly have expired by now. In addition, European readers can ignore this entirely – software patents just aren’t a thing.
(This is a guest post by Antoni Sawicki aka Tenox)
I have recently acquired this artifact:

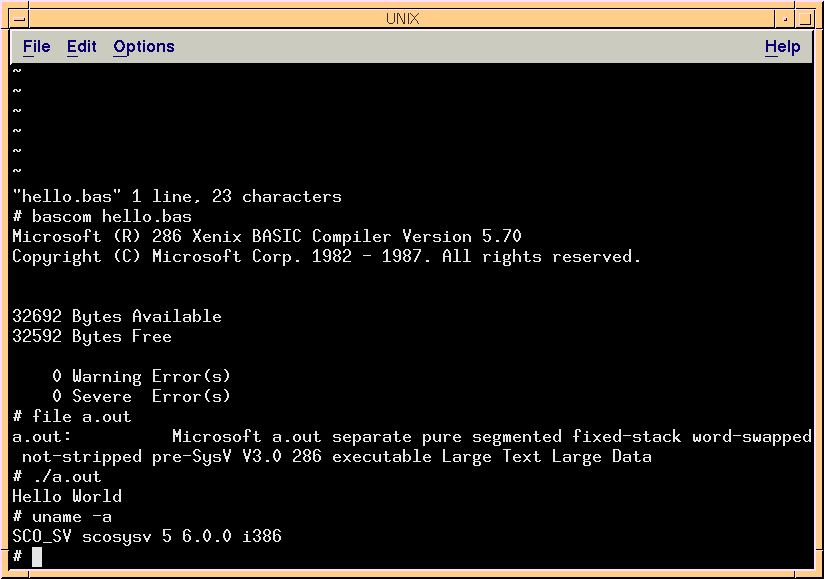
It’s the Microsoft BASIC compiler for XENIX 286 Operating System. Compiler as opposed to just BASIC interpreter, it can produce executable a.out files, similar to C compiler for example.
Carefully removed the shrink wrap. Inside were couple of 5.25″ floppies, registration card and a manual:

Interestingly the 32 year old disks read just fine on a first attempt. I need to start backing up important files to 5.25″ floppy disks as they seem to outlast everything else.
Thanks to efforts of Michal Necasek from OS/2 Museum now you can run Microsoft XENIX 286 in Virtual Box.
The disks can be installed in to XENIX running on Vbox following a few simple steps:
tar xvf /dev/fd0
./msinstall /dev/fd0
Upon installation you invoke the compiler like this:
bascom demo.bas
./a.out
And it produced an a.out executable which worked perfectly fine.
It’s fun to write BASIC code in vi editor, which I just realized I never done before.
Curiously the compiler also worked on the brand spanking new Xenix 2018, or rather I should call it Open Server 6, which you can download here.
The BASIC compiler is available for download from my archive along with the manual in pdf.
(This is a guest post from Antoni Sawicki aka Tenox)
I spend most of time in a day staring at a terminal window often running various performance monitoring tools and reading metrics.
Inspired by tools like gtop, vtop and gotop I wished for a more generic terminal based tool that would visualize data coming from unix pipeline directly on the terminal. For example graph some column or field from sar, iostat, vmstat, snmpget, etc. continuously in real time.
Yes gnuplot and several other utilities can plot on terminal already but none of them easily read data from stdin and plot continuously in real time.
In just couple of evenings ttyplot was born. The utility reads data from stdin and plots it on a terminal with curses. Simple as that. Here is a most trivial example:
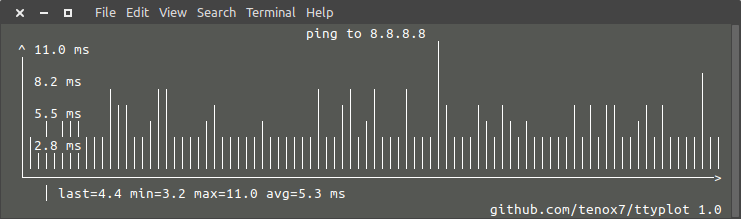
To make it happen you take ping command and pipe the output via sed to extract the right column and remove unwanted characters:
ping 8.8.8.8 | sed -u 's/^.*time=//g; s/ ms//g' | ttyplot
Ttyplot can also read two inputs and plot with two lines, the second being in reverse-video. This is useful when you want to plot in/out or read/write at the same time.
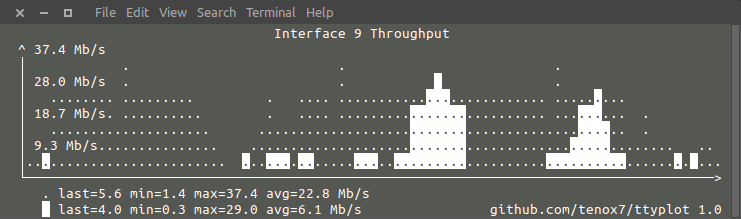
A lot of performance metrics are presented in as a “counter” type which needs to be converted in to a “rate”. Prometheus and Graphana have rate() or irate() function for that. I have added a simple -r option. The time difference is calculated automatically. This is an example using snmpget which is show in screenshot above:
{ while true; do snmpget -v 2c -c public 10.23.73.254 1.3.6.1.2.1.2.2.1.{10,16}.9 | gawk '{ print $NF/1000/1000 }'; sleep 10; done } | ttyplot -2 -r -u "MB/s"
I now find myself plotting all sorts of useful stuff which otherwise would be cumbersome. This includes a lot of metrics from Prometheus for which you normally need a web browser. And how do you plot metrics from Prometheus? With curl:
{ while true; do curl -s http://10.4.7.180:9100/metrics | grep "^node_load1 " | cut -d" " -f2; sleep 1; done } | ttyplot
If you need to plot a lot of different metrics ttyplot fits nicely in to panels in tmux, which also allows the graphs to run for longer time periods.
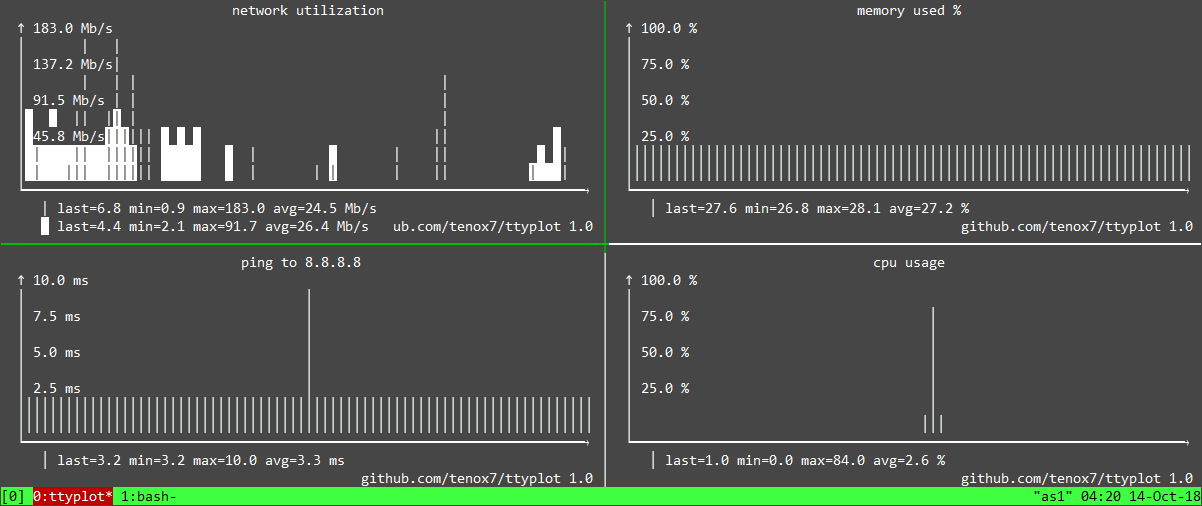
Of course in text mode the graphs are not very precise, but this is not the intent. I just want to be able to easily spot spikes here and there plus see some trends like up/down – which works exactly as intended.I do dig fancy braille line graphs and colors but this is not my priority at the moment. They may get added later, but most importantly I want the utility to work reliably on most operating systems and terminals.
You can find compiled binaries here and source code and examples to get you started – here.
If you get to plot something cool that deserves to be listed as an example please send it on!
(This is a guest post by Antoni Sawicki aka Tenox)
Microsoft is releasing Windows 10 for ARM64 CPUs and this time, unlike Windows RT fiasco, there will be a full desktop app support including a dynamic binary translator to allow running existing x86 apps on ARM CPU, much like FX!32 on Alpha NT or Rosetta on Mac OS X.
Latest Visual Studio updates now bring official ARM/ARM64 support for Desktop Apps, little hidden, but here is how to enable it.
Being able to compile Windows ARM apps, I wanted to try to actually run them, but … on what exactly? There are some developer evaluation boards. Apparently someone managed to run it on Raspberry PI. Most importantly however you can run Windows 10 ARM64 on QEMU. This is some serious Fun With Virtualization!
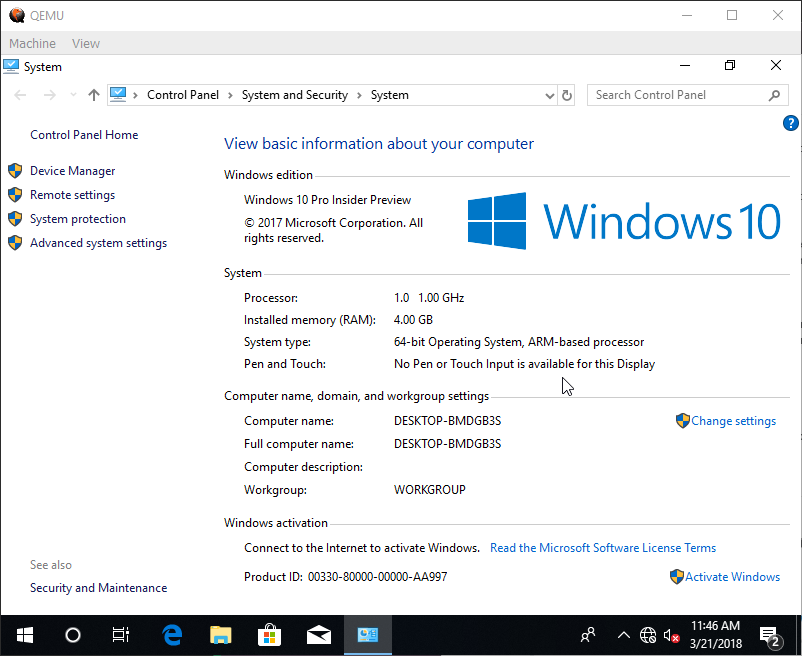
Windows 10 ARM64 running on QEMU
I’m not claiming to be the first. Clever people have already done it. I just wanted to make it little easier for the lazier of us. Here is how.
Follow the link above but skip the shady UUP business in step #3 and download ready made iso instead. You can google the iso image from windows.cmd and it will take you to this link. You need the rest of the files like UEFI firmware and virtio drivers.
For the even more impatient here is a ready to run image with Windows pre-installed. Because QEMU now comes with DLL HELL I’m not including it in the archive. You will have to install it separately.
If you want to transfer files in/out of the image a tip from Pete Batard of Rufus:
Create a folder named say “transfer” and add the following option to the launch script:
-hdb fat:rw:transferThis will create a second FAT32 formatted disk, that maps your transfer\
directory to the QEMU virtual machine. In our case, Windows 10 will see it
and make it automatically accessible as “QEMU VVFAT (D:)”. You can even
use this to write file from the VM to the host (though, depending on how
fast Windows flushes its disk cache, they may take a while to appear).
Go have fun and port some apps to ARM64 with free community edition of Visual Studio. I’m going to start with Aclock 🙂
(This is a guest post by Antoni Sawicki aka Tenox)
In a recent blog post Wanted: Console Text Editor for Windows I lamented about lack of a good console/cmd/PowerShell text editor for Windows. When researching for the article I made rather interesting discovery. There in a fact has been a native Windows, 32bit, console based text editor. It was available since earliest days of NT or even before. But let’s start from…
…in the beginning there was Z editor. Developed by Steve Wood for TOPS-20 operating system in 1981. Some time after that, Steve sold the source code to Microsoft, which was then ported to MS-DOS by Mark Zbikowski (aka the MZ guy) to become the M editor.
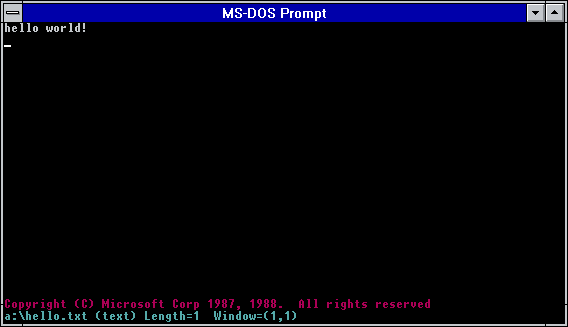
The DOS-based M editor was included and sold as part of Microsoft C 5.1 (March 1988), together with the OS/2 variant, the MEP editor (perhaps M Editor Protected-mode). The official name of M/MEP was simply Microsoft Editor. The same editor was also available earlier (mid-1987) as part of the MS OS/2 SDK under a different name: SDKED. Note that normally SDKED insists in operating in full screen mode. Michal Necasek generously spent his time and patched it up so that it can be run in windowed mode for your viewing pleasure.

However my primary interest lies with Windows NT. The NT Design Workbook mentions that in the early days a self-hosting developer workstation included compiler, some command line tools and a text editor – MEP. Leaked Windows NT builds sometimes include IDW, Internal Development Workstation, which also seem to contain a variant of the same editor. In fact some these tools including MEP.EXE can be found on Windows NT pre-release CD-ROMs (late 1991) under MSTOOLS. It was available for both MIPS and 386 as a Win32 native console based application.
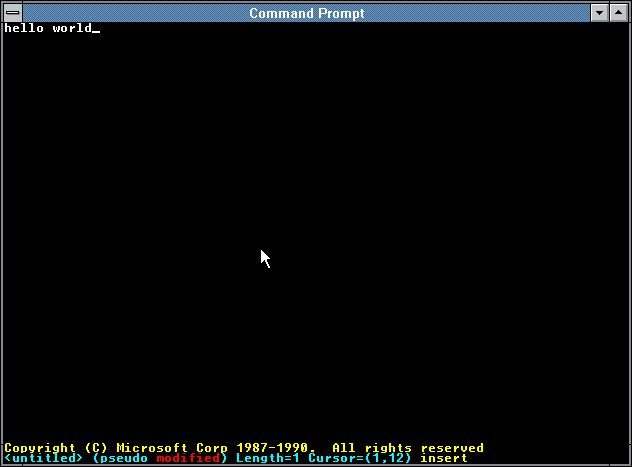
The editor was later also available for Alpha, i386, MIPS, and PowerPC processors on various official Windows NT SDKs from 3.1 to 4.0. It survived up to July 2000 to be last included in Windows 2000 Platform SDK.
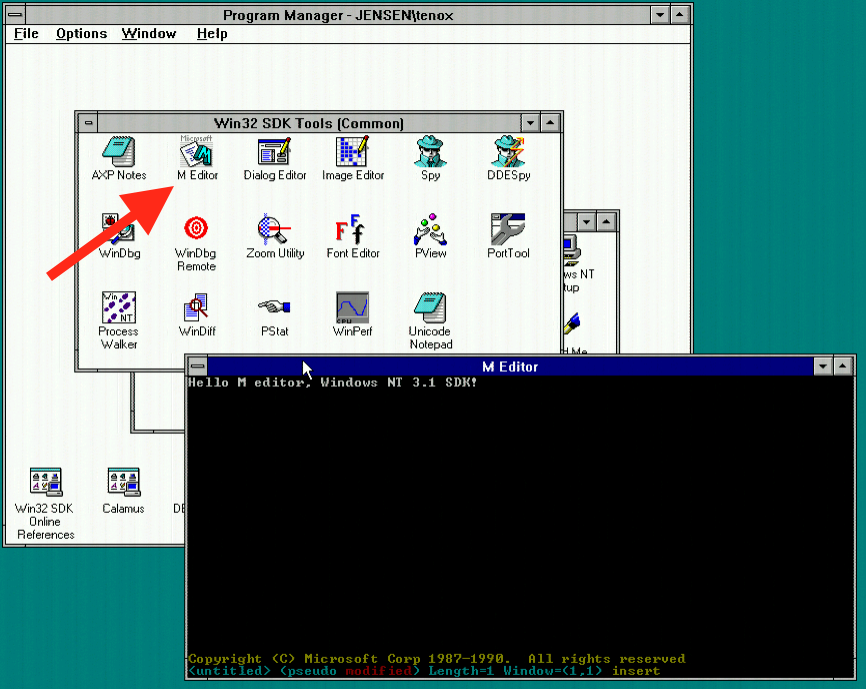

The Win32 version of MEP also comes with an icon and a file description which calls it M Editor in NT 3.1 SDK and later Microsoft Extensible Editor.

From time perspective, it was rather unfortunate that this gem was buried in the SDK rather than being included on Windows NT release media. However I can understand that the editor wasn’t very user friendly or intuitive, compared to say edit.com from MS-DOS. It came from a different era and similar to VI or Emacs, didn’t have “PC user friendly” key bindings or menus.
But that’s not the end of the story. The editor of many names survives to this day, at least unofficially. If you dig hard enough you can find it on OpenNT 4.5 build. For convenience, this and other builds including DOS M, OS/2 MEP and SDKED, NT SDK MEP can be downloaded here.
Digging through the archive I found not one but two copies of the editor code, lurking in the source tree. One under the name MEP inside \private\utils\mep\ folder and a second copy under name Z (which was the original editor for TOPS) in \private\sdktools\z folder. MEP was included in Platform SDK, while Z was only available as part of IDW.
Doing a few diffs I was able to get some insight on the differences. Looks like MEP was initially ported from OS/2 to NT and bears some signs of being an OS/2 app. The Z editor on the other hand is a few years newer and has many improvements and bug fixes over MEP. It also uses some specific NT only features.
Sadly the internal Z editor was never released anywhere outside of Redmond. All the versions outlined so far had copyrights only up to 1990, while Z clearly has copyright from 1995. Being a few years newer and more native to NT I wanted to see if a build could be made. With some effort I was able to separate it from the original source tree and compile stand alone. Being a pretty clean source code I was able to compile it for all NT hardware platforms, including x64, which runs comfortably on Windows 10. You can download Z editor for Windows here.
Platform SDK contains pretty solid documentation in tools.chm.
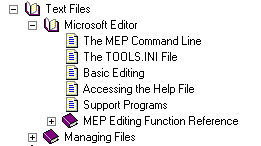
Here is a handy cheat sheet:

Last but not least there is a modern open source re-implementation of Z editor named K editor. It’s written from scratch in C++ and LUA and has nothing to do with the original MEP source code. K is built only for x64 using Mingw. There are no ready to run binaries so I made a fork and build.
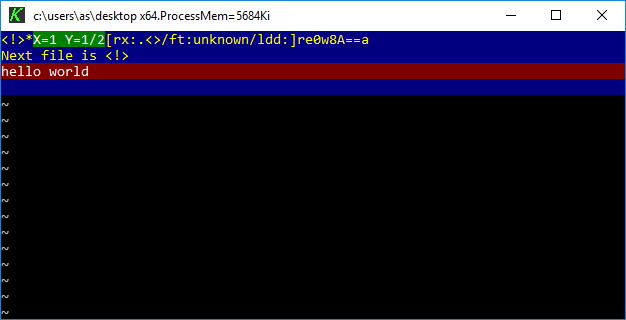
The author Kevin Goodwin has kindly included copies of original documentation if you actually want to learn how to use this editor.
(This is a guest post by xorhash.)
Did I say I’m done with UNIX Seventh Edition (V7)? How silly of me; of course I’m not. V7 is easy to study, after all.
Something that’s always bothered me about the stdio.h primitives fread() and fwrite() are their weak guarantees about what they actually do. Is a short read or write “normal†in the sense that I should normally expect it? While this makes no answer about modern-day operating systems, a look at V7 may enlighten me about what the historical precedent is.
As an aside: It’s worth noting that the stdio.h functions are some of the few that require a header. It was common historical practice not to declare functions in headers, just see crypt(3) as an example.
I will first display the man page, then ask the questions I want to answer, then look at the implementation and finally use that gained knowledge to answer the questions.
The man page for fread() and fwrite() is rather terse. Modern-day man pages for those functions are equally terse, though, so this is not exactly a novelty of age. Here’s what it reads:
fread, fwrite – buffered binary input/output
#include <stdio.h>
fread(ptr, sizeof(*ptr), nitems, stream)
FILE *stream;
fwrite(ptr, sizeof(*ptr), nitems, stream)
FILE *stream;
Fread reads, into a block beginning at ptr, nitems of data of the type of *ptr from the named input stream. It returns the number of items actually read.
Fwrite appends at most nitems of data of the type of *ptr beginning at ptr to the named output stream. It returns the number of items actually written.
read(2), write(2), fopen(3), getc(3), putc(3), gets(3), puts(3), printf(3), scanf(3)
Fread and fwrite return 0 upon end of file or error.
So there are the following edge cases that are interesting:
fread(): If sizeof(*ptr) is greater than the entire file, what happens?sizeof(*ptr) * nitems overflows, what happens?fread()Note: All file paths for source code are relative to /usr/src/libc/stdio/ unless noted otherwise. You can read along at the TUHS website.
rdwr.c implements fread(). fread() is simple enough; it’s just a nested loop. The outer loop runs nitems times. The outer loop sets the number of bytes to read (sizeof(*ptr)) and runs the inner loop. The inner loop calls getc() on the input FILE *stream and writes each byte to *ptr until either getc() returns a value less <Â 0 or all bytes have been read.
/usr/include/stdio.h implements getc(FILE *p) as a C preprocessor macro. If there is still data in the buffer, it returns the next character and advances the buffer by one. Interestingly, *(p)->_ptr++&0377 is used to return the character, despite _ptr being a char *. I’m not sure why that &0377 (&0xFF is there. If there is no data in the buffer, it instead returns _filbuf(p).
filbuf.c implements _filbuf(). This function is a lot more complex than the other ones until now. It begins with a check for the _IORW flag and, if set, sets the _IOREAD flag as well. It then checks if _IOREAD is not set or if _IOSTRG is set and returns EOF (defined as -1 in stdio.h) if so. These all seem rather inconsequential to me. I can’t make heads or tails of _IOSTRG, however, but it seems irrelevant; _IOSTRG is only ever set internally in sprintf and sscanf for temporary internal FILE objects. After those two flag checks, _filbuf() allocates a buffer into iop-<_base, which seems to be the base pointer of the buffer. If flag _IONBF is set, which happens when setbuf() is used to switch to unbuffered I/O, a temporary, static buffer is used instead. Then read() is called, requesting either 1 bytes if unbuffered I/O is requested or BUFSIZ bytes. If read() returned 0, the FILE is flagged as end-of-file and EOF is returned by _filbuf(). If read() returned <0, the FILE is flagged as error and EOF is returned by _filbuf(). Otherwise, the first character that has been read is returned by _filbuf() and the buffer pointer incremented by one.
According to its man page, read() only returns 0 on end-of-file. It can also return -1 on “many conditionsâ€, namely “physical I/O errors, bad buffer address, preposterous nbytes, file descriptor not that of an input fileâ€
As an aside, BUFSIZ still exists today. ISO C11 § 7.21.2 no. 9 dictates that BUFSIZ must be at least 256. V7 defines it as 512 in stdio.h. One is inclined to note that on V7, a filesystem block was understood 512 bytes length, so this was presumably chosen for efficient I/O buffering.
fwrite()rdwr.c also implements fwrite(). fwrite() is effectively the same as fread(), except the inner loop uses putc(). After every inner loop, a call to ferror() is made. If there was indeed an error, the outer loop is stopped.
/usr/include/stdio.h implements putc(int x, FILE *p) as a C preprocessor macro. If there is still room in the buffer, the write happens into the buffer. Otherwise, _flsbuf() is called.
flsbuf.c implements _flsbuf(int c, FILE *iop). This function, too, is more complex than the ones until now, but becomes more obvious after reading _filbuf(). It starts with a check if _IORW is set and if so, it’ll set _IOWRT and clear the EOF flag. Then it branches into two major branches: the _IONBF branch without buffering, which is a straight call to write(), and the other branch, which allocates a buffer if none exists already or otherwise calls write() if the buffer is full. If write() returned less than expected, the error flag is set and EOF returned. Otherwise, it returns the character that was written.
According to its man page, write() returns the number of characters (bytes) actually written; a non-zero value “should be regarded as an errorâ€. With only a cursory glance over the code, this appears to happen for similar reasons as read(), which is either physical I/O error or bad parameters.
In fread(): If sizeof(*ptr) is greater than the entire file, what happens?
On this under-read, fread() will end up reading the entire file into the memory at ptr and still return 0. The I/O happens byte-wise via getc(), filling up the buffer until getc() returns EOF. However, it will not return EOF until a read() returns 0 on EOF or -1 on error. This result may be meaningful to the caller.
If sizeof(*ptr) * nitems overflows, what happens?
No overflow can happen because there is no multiplication. Instead, two loops are used, which avoids the overflow issue entirely. (If there are strict filesystem constraints, however, it may be de-facto impossible to read enough bytes that sizeof(*ptr) * nitems overflows. And of course, there’s no way you could have enough RAM on a PDP-11 for the result to actually fit into memory.)
Is the “number of items actually read/written†guaranteed to be the number of items that can be read/written (until either EOF or I/O error)?
Partially: Both fread() and fwrite() short-circuit on error. This causes the number of items that have actually been read or written successfully to be returned. The only relevant error condition is filesystem I/O error. Due to the byte-wise I/O, it’s possible that there was a partial read or write for the last element, however. Therefore, it would be more accurate to say that the “number of items actually read/written†is guaranteed to be the number of non-partial items that can be read/written. A short read or short write is an abnormal condition.
Is the “number of items actually written†guaranteed to have written every item in its entirety?
No, it isn’t. A partial write is possible. If a series of structs is written and then to be read out again, however, this is not a problem: fread() and fwrite() only return the count of full items read or written. Therefore, the partial write will not cause a partial read issue. If a set of bytes is written, this is an issue: There will be incomplete data – possibly to be parsed by the program. It is therefore to preferable to write (and especially read) arrays of structs than to write and read arrays of bytes. (From a modern-day perspective, this is horrendous design because this means data files are not portable across platforms.)
What qualifies as error?
Effectively, only a physical I/O error or a kernel bug. Short fread() or fwrite() return values are abnormal conditions. I’m not sure if there is the possibility that the process got a signal and the current read() or write() ends up writing nothing before the EINTR; this seems to be more of a modern-day problem than something V7 concerned itself.
Updates:
(This is a guest post by Antoni Sawicki aka Tenox)
Since 2012 or so, Microsoft has been pushing concept of running Windows Server “headless”, without GUI, and administering everything through PowerShell. I remember sitting through countless TechEd / Ignite sessions year after year, and all I could see were blue PowerShell command prompts everywhere. No more wizards, forms, dialogs. MMC and GUI based administration is suddenly thing of a past. Just take a look at Server Core, WinPE, Nano, PS Remoting, Windows SSH server, Recovery Console and Emergency Management Services. Even System Center is a front end for PowerShell. Nowadays everything seems to be text mode.
This overall is good news and great improvement since previous generations of Windows, but what if you need to create or edit a PowerShell, CMD script or some config file?
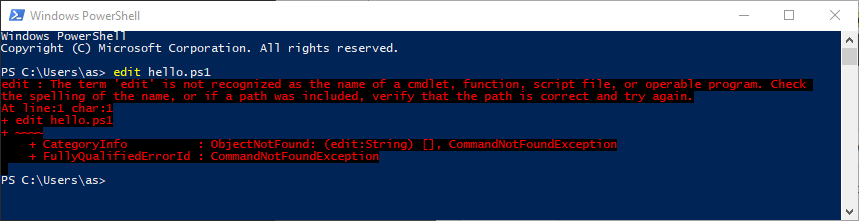
Oooops, looks like you are screwed. Seems that Redmond forgot to include most crucial tool in sysadmins, or developers job – a simple text mode editor. WTF Microsoft?
So, are there any 3rd party alternatives? Yes, and there are and quite a lot of them! Unfortunately none are perfect and most are old and unmaintained. This article aims to be a grand tour of whatever is available out there.
Note that throughout the article I will be repeatedly referring to a “portable” editor. For me this means a single .exe file, that can be carried around on a USB pen drive or network share. I also cry a lot about 64-bit Windows builds because I work a lot in WinPE and other environments where syswow64 is not available.
First lets start with most obvious choices, well known through years. If you search for a Windows Console Editor VIM and Emacs will naturally pop up first. These editors don’t need any introduction or praising. I use VIM every day and Emacs every now and then. These two had ports to Windows for as long as I can remember and in terms of quality and stability definitely up top. The problem is that both are completely foreign and just plain unusable to a “typical Windows user”. The learning curve of weird key controls is pretty steep. Also portability suffers a lot, at least for Emacs. Both editors come with hundreds of supporting files and are massive in size. Emacs.exe binary is whopping 83 MB in size and the zip file contains two of them just in case. Whole unpacked folder is 400 MB. WTF.
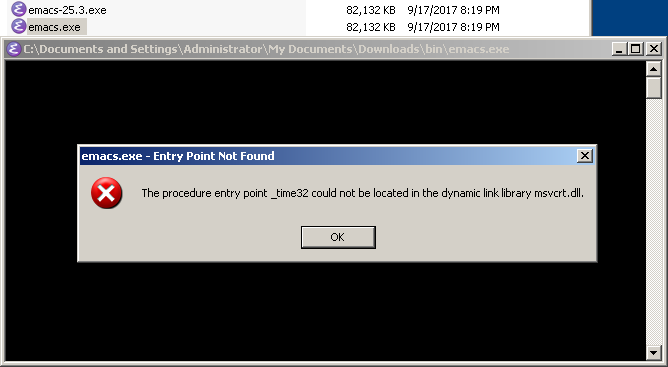
Emacs on Windows Console
VIM is fortunately much much better you can extract single vim.exe binary from the package and use it without much complaints:
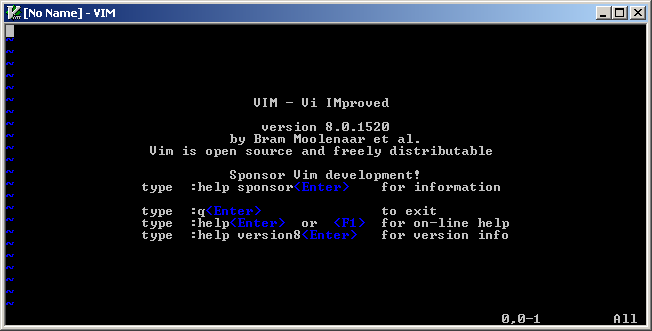
VIM on Windows Console
When talking about about VI and Emacs hard not to mention some more historical versions. Emacs’ little brother MicroEmacs has been available for Windows since earliest days. I’m not going to attempt to link to any particular one since there are so many flavors.
MicroEmacs
VIM little brother VI also comes in different shapes and forms. Lets take look at a few.
Elvis on Windows
XVI on Windows
Stevie is a very special case. Rumor has it, this editor played crucial role in development of Windows NT itself and has been included since earliest days of NT as part of the Internal Developer Workstation. Because it was ported by folks at Redmond the quality should be pretty good. Unfortunately README states “this is an incomplete VI that has not been fully tested. Use at your own risk.”. For a historical note according to Wikipedia, Stevie port to Amiga has been used by Bram Moolenaar as a base source code for VIM. NT VI is available as part of Windows NT Resource Kit (Reskit).
Stevie for Windows aka NT VI, part of Internal Developer Workstation and NT Resource Kit (Reskit)
One particularly interesting case is VI editor from Watcom compiler suite. It has very nice TUI known from MS-DOS editors, syntax highlighting and online help. One of nicest versions of VI available for Windows. Small portable and just all around handy editor. This is probably my main to go text editor when working on WinPE or Server Core. Unfortunately not very well known. I hope it can gain some popularity it deserves.
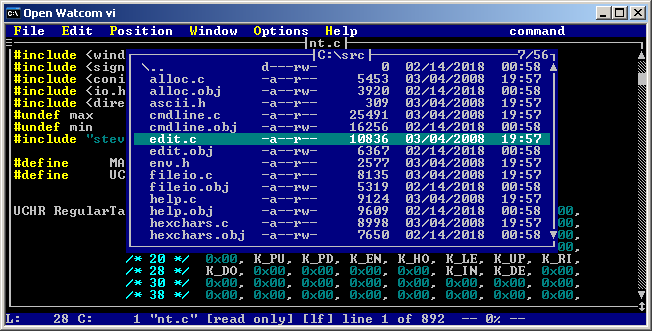
OpenWatcom VI Editor
Thanks to Federico Bianchi just learned that there is a BusbyBox port to Windows having both 32bit and 64bit builds, 100% portable as just a single exe file! Most importantly it contains a working vi editor that understands window resizing and Win32 paths. I’m going to be keeping this one around. Awesome job Busybox! As a last thought I wish they also included Nano.
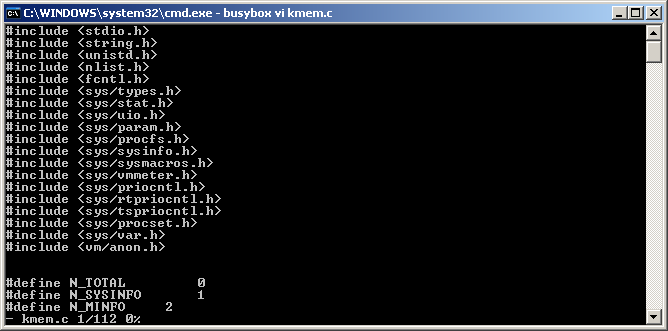
BusyBox Win32 VI Editor
I don’t want this article to be all about VI and Emacs clones. Let this nice color menus be a segue to more native Windows / DOS editors at least departing from hardcore keystrokes and Unix.
For a change in theme lets look at SemWare TSE Pro, the editor that originally started as QEDIT for DOS and OS/2. It has most advanced features one could ever imagine for a text mode editor. Including resizable windows, hex editor, macros and spell checker. I really wish I could use it in everyday’s life. Unfortunately TSE has some drawbacks, it lacks portable version and install is little cumbersome. Currently no x64 build but the author is working on it. TSE is not free, the license is $45 but it allows to install on as many machines as you need. UPDATE: TSE is now Freeware!

SemWare TSE Pro
Next one up is Brief. It used to be very popular in it’s own time and sparked quite bit of following as there are numerous of editors being “brief style”. It’s a nice and small console based text editor. It comes in two versions basic (free) and professional (paid). The pro version supports splitting in to multiple windows regexp and unicode. Unfortunately it runs at $120 per user and there is no 64bit build or a portable edition.
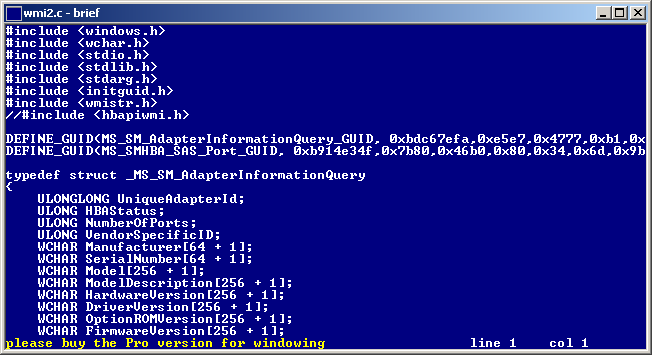
Brief
There also is an open source clone of Brief called GRIEF. Flipping through the manual it has very impressive set of features including $120 windowing feature and macros. Unfortunately it’s rather unportable due to large amount of dll and other files. 64bit build could probably be made if someone wanted.
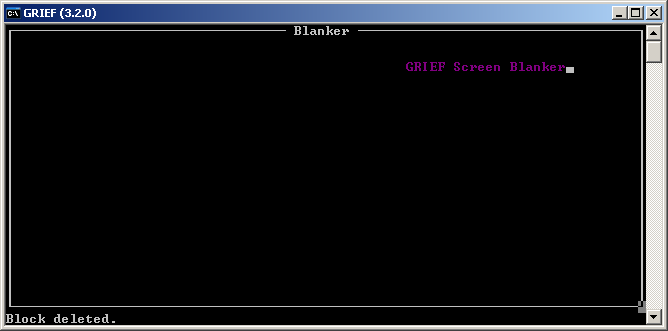
GRIEF free Brief Clone
As we talk about less costly options there is Kinesics Text Editor aka KIT. It’s more well known if you search on google, completely free and after installing you can find and a x64 binary file! This makes it somewhat portable and able to run in WinPE for instance. Until recently the editor did not have 64bit version so I did not have chance to use it much in practice but the TUI appears to have a well rounded easy to use (F1 or right mouse click brings menus). It does’t seem to have any advanced features but it’s very stable and actively maintained. And frankly this is what matters for editing on the console. It may actually be the right missing Windows console editor.
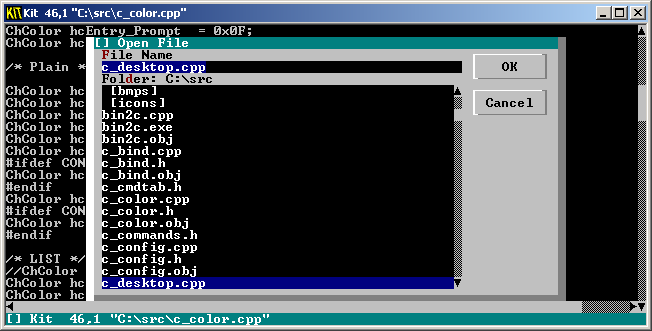
Kinesics aka KIT
Another one is Minimum Profit. It’s fully open source and it supports a lot of platforms in both windowing and text mode. It has a lot of interesting features such as syntax highlighting, spell checked and menus. It can’t be easily made portable as it needs a lot of files of it’s own scripting language. I also find that screen refresh is somewhat funky. UPDATE: 64bit version now available!
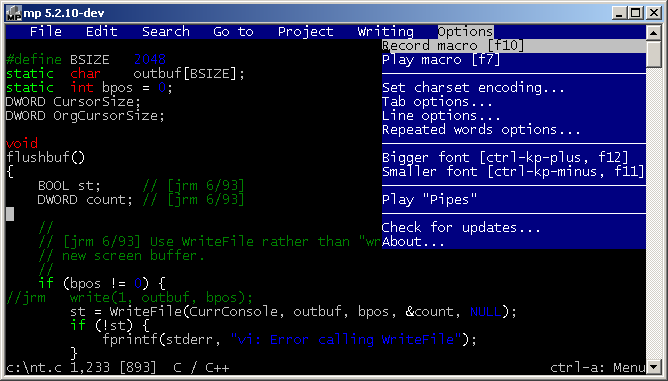
Minimum Profit
Lets look at somewhat well known FTE. It’s a very nice text editor available on many platforms such QNX, OS/2 and of course Windows. It has nice TUI, split windows, syntax highlighting, folding, bookmarks and tools for HTML authoring etc. Overall awesome editor falling short only to TSE. Support for NT console has been available since 1997. I have recently fixed couple of bugs and built a 64bit portable version.
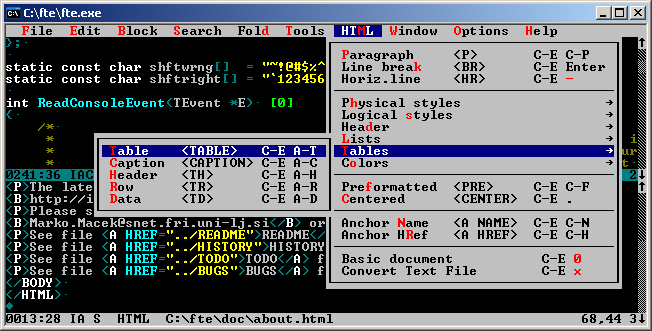
FTE Editor
One could also not forget Borland Turbo C IDE. Apparently there is an open source clone of the IDE as a regular editor called SETEdit. It’s multi platform editor with MS-DOS style windows and menus. Syntax highlighting macros and all regular amenities. Looks like DOS version can play MP3 songs while you code. There is a native WinNT build made with BCPP. To run on Windows you install the DOS version then overwrite dos exe file win NT exe. The editor is absolutely awesome, unfortunately currently doesn’t work in a portable manner and there is no x64 binary. However as it’s open source it could be probably made.
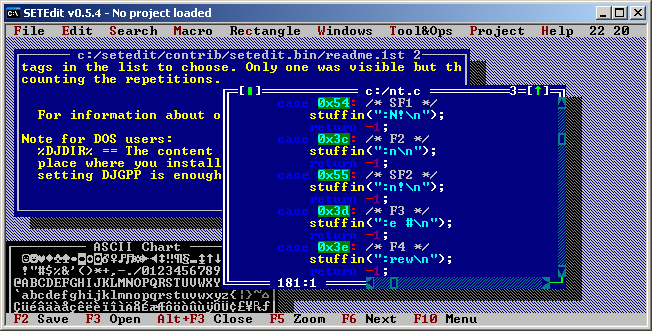
SETEdit a Borland Turbo C IDE Clone
When talking about MS-DOS style windows, Norton Commander like file managers come to mind. There is one particular built specifically for Windows – FAR Manager. Written by author of WinRAR, originally shareware, but since 2007 it has been released under BSD license. FAR does come with a built in text editor hence it’s featured here. It’s actively supported and developed, and because it’s designed from ground up for Windows, it’s probably most stable and trustworthy of all applications in this post. I normally don’t use it that much, but I do keep a copy of it lying around when I need to do some more heavy lifting from Windows console. There is a 64bit binary by default but unfortunately FAR can be hardly made portable as it comes with 400 files.
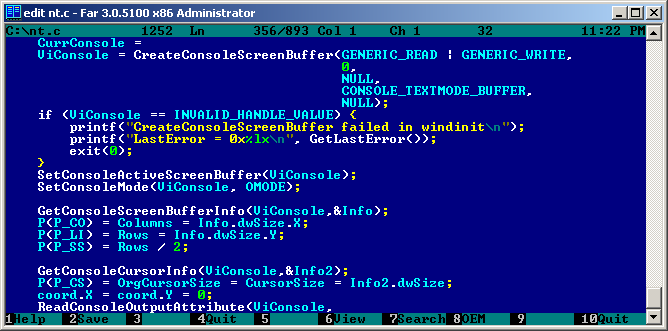
FAR Manager Text Editor
When talking about Norton Commander clones lets not forget Midnight Commander, which does have an unofficial native Windows console build called mcwin32. Similar to FAR, MC has a very nice built-in text editor. MC overall seems far nicer than FAR but because it’s multi platform rather than WIndows specific and not officially supported I don’t trust it as much for day to day use.
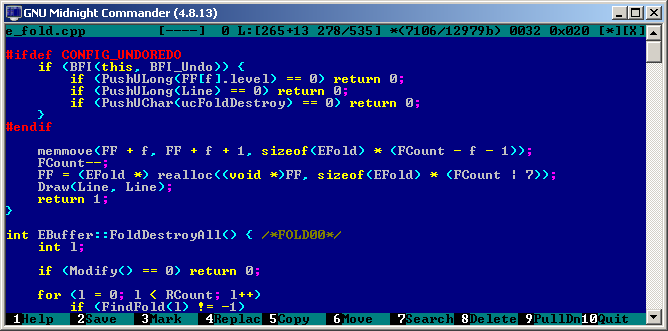
GNU Midnight Commander
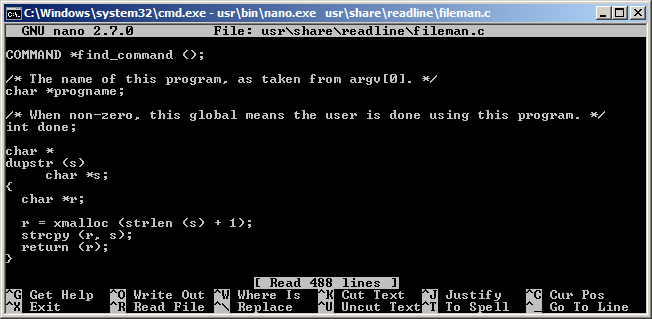
When on topic of Unix, lets talk about GNU Nano. In it’s native habitat, it’s very popular and stable editor making it a perfect choice for a text mode console. Unfortunately Windows port is lacking quite a lot, especially for things like resizing Window or handling file names. The official build looks like a fusion of cygwin, mingw, pdcurses and other horrible stuff. Version that comes with Mingw/MSYS is not portable and so far I failed in attempts to build a static windows binary by hand. Nano predecessor UW Pico unfortunately never did have console terminal Windows port. Authors of Pine decided to make it semi graphical application with it’s own window, menus and buttons. Sad story for both Pico and Nano. Hopefully one day someone will make a 100% native Windows port.
Another non-vi and non-emacs Unix editor with Windows console port is JED. Frankly I have not used JED that much in the past although I did play with it in the 90s. This is the original web page of Jed editor. It does seem to have menus and multi windows. Unfortunately doesn’t look like it can be easily made in to a portable image.
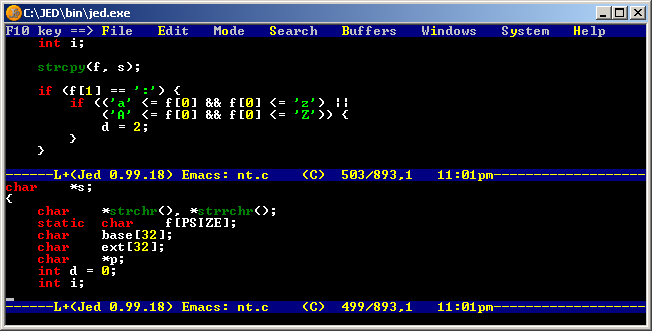
JED Win32 Port
Yet another more obscure editor is ED-NT which is DEC EDT clone. Unfortunately seems to be completely dead an unmaintained. Sources are still available through archive.org so perhaps it could be still looked after if someone wanted EDT editor on Windows.
ED-NT
When going through obscurities via archive.org one can also mention ZABED and more specifically Z95 which is a 32bit console version. I don’t know anything about the editor and I’m little too lazy to play with it extensively although pdf manual is available. Probably little too old and too obscure for every day use.
Z95
Perhaps even more obscure to a mere mortal is The Hessling Editor aka THE. It’s based on VM/CMS editor XEDIT. I did briefly use VM/CMS and XEDIT in early ’90 but I never liked it so much. THE comes in as a native Win32 binary. Not easily portable as it requires some additional files. Also no 64bit binary but source code is available.
THE aka The Hessling Editor
Thanks to Andreas Kohl I have learned about X2 Programmers Editor which also has NT console version. The editor seems very nice and has extensive help, syntax highlighting, etc. Unfortunately I have never used this editor before. Last version has been released in 2008 which is not loo long ago but sadly there has been no update since. I hope the author will continue to maintain it.
X2 Programmers Editor
Andreas also brought up Personal Editor, which comes as PE32 and PE64. Looks like really well maintained and stable editor designed and developed specifically for Windows. 64bit bit version is really cool however the editor doesn’t seem to be portable and $40 license will probably prevent me from using it professionally in environments where I would need it. Never the less looks like a very fine editor!
Another find is e3 editor. Pretty interesting stuff. It’s written in assembler and available on many operating systems including DOS and Windows. Looks like it’s still maintained as last version was released in 2016. It supports multiple modes, Wordstar, Emacs, Vi, Pico and Nedit by renaming or linking the main executable. It’s definitely portable as it doesn’t need any extra files and the exe is just 20KB (take that emacs!). Unfortunately because of assembler I don’t think there will be a 64bit release any time soon. Overall seem to be really cool to keep this one around.
e3 editor
A really cool last minute find is public domain TDE – Thomson-Davis Editor. Released not so long ago in 2007 it has 16, 32bit DOS and 32bit Windows console executable. It has DOS style menus,syntax highlighting, resizable windows and bunch of other features. Looks like a very handy editor. I don’t know how did I miss it. Since source code was available so I was able to make a x64 build. This is really untested so use at your own risk!
TDE
Also a recent find – shareware editor called Aurora. I never had a chance to use it in the past but after taking it for a quick spin I fell in love. The text mode UI it feels like it’s own windowing operating system! Originally for DOS, Unix and OS/2, Win32 port is relatively new. Unfortunately it’s no longer maintained or even sold. This is very sad because the editor is extremely cool. I hope the author may be willing to release the source code so it could be maintained.
Aurora
Thanks to Richard Wells I have learned about OSPlus Text Editor. It’s a really cool little editor with Borland style TUI and multi windows. It doesn’t seem to have any advanced features but it does have a built in calculator and allows background play of WAV and MID. Also allows format conversion of various formats like Word, Write or RTF in to text using Microsoft Office converters. Pretty cool if you need to read Word based documentation on the text console. Sadly looks like the application is no longer maintained. I guess with little bit of luck a 64bit version could be compiled using Mingw64 or MSVC.
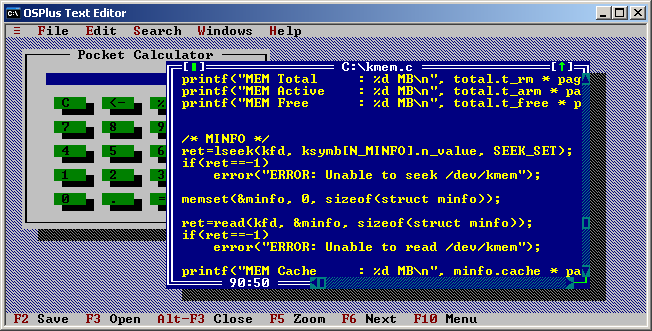
OSPlus Text Editor
Also recently learned about HT. This is more intended as a binary/exe/hex editor and analyzer. However it seems to have an excellent plain text editor with HTML and C syntax highlighting. It doesn’t have very advanced features but one that stands out is a very detailed change log, much like Photoshop History. It shows you what exactly has been changed and in what order. This is pretty cool when doing heavy editing of some important files. The latest version is from 2015 and it’s 100% portable single exe. Unfortunately no x64 but I guess it should be easy enough to build one with Mingw64.
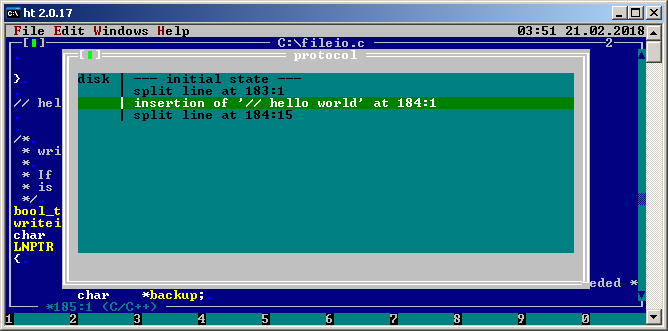
HT
Just in, freshly “re-discovered” – Microsoft Editor. This editor is a Win32 port of Mark Zbikowski’s port of Z editor to MS-DOS. It has been widely used with Microsoft C as M, MEP and and OS/2 SDK as SDKED. Shockingly looks like Windows NT did actually have a console mode text editor since it’s earliest days or even earlier. Included in Windows NT pre-release CDs and later on the official Windows NT/2000 SDKs, hiding in plain sight, was a Win32 console mode MEP.EXE. Only if Microsoft included this editor with Windows itself the world would be a different place. I have recently dug it out of SDK and made available here. There also are additional builds (including x64) here. There is a dedicated blog post about it.
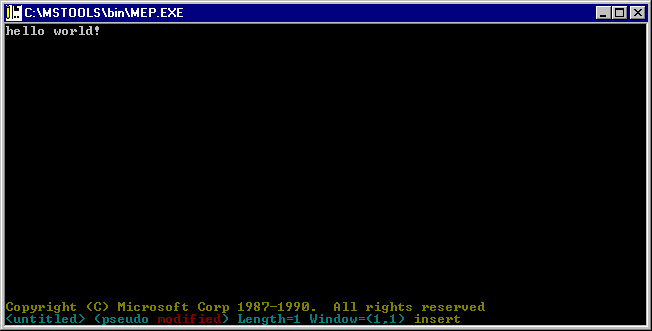
Microsoft Editor aka MEP aka Z
As with many commercial editors there is an open source edition of Z named K_Edit. It is a modern re-implementation from scratch written in C++ and LUA. It builds only on 64bit Windows and there probably is no chance for any other version. As of today author of K doesn’t provide ready binaries but I was able to make one myself.
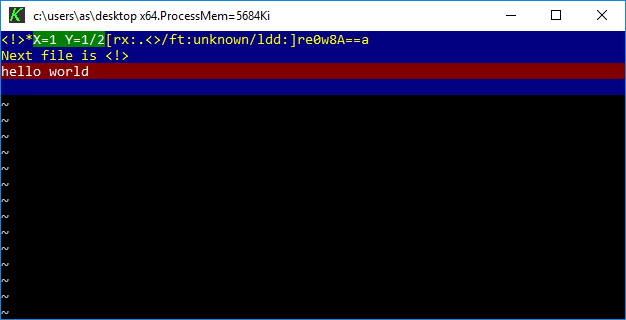
K editor on Windows 10 x64
Reader brdlph pointed me to a pretty fresh editor named Textadept. It’s a cross platform, both GUI and TUI editor. Windows console version uses Curses, but it performs remarkably well. It has a look and feel of a modern programmer’s text editor with syntax highlighting, line numbers, etc. The zip archive comes with over 400 files so it’s rather not portable. Also there seem to be no Windows 64bit build although there is one for Linux. The application seem to be very well maintained and the latest release is from January 2018!
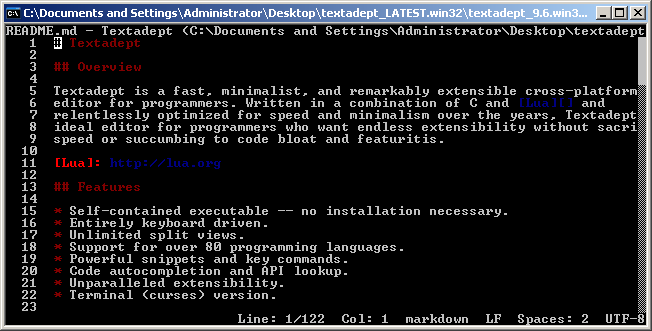
Textadept
Reader Andreas Kohl mentioned SlickEdit, which was a text mode editor for DOS, OS/2 and Windows console (before Visual SlickEdit stole it’s name). According to the company’s employee an OS/2 version of the editor was used by some Windows NT team members to develop their operating system. In early days, SlickEdit CTO traveled to Redmond to port the application to a barely yet functioning NT console system so that the developers could use native dev environment. SlickEdit was most likely the very fist commercial application for Windows NT. It was available in 386, Alpha, MIPS and PowerPC editions. I’m hoping to obtain old evaluation copies. So far I was able to get this screenshot:
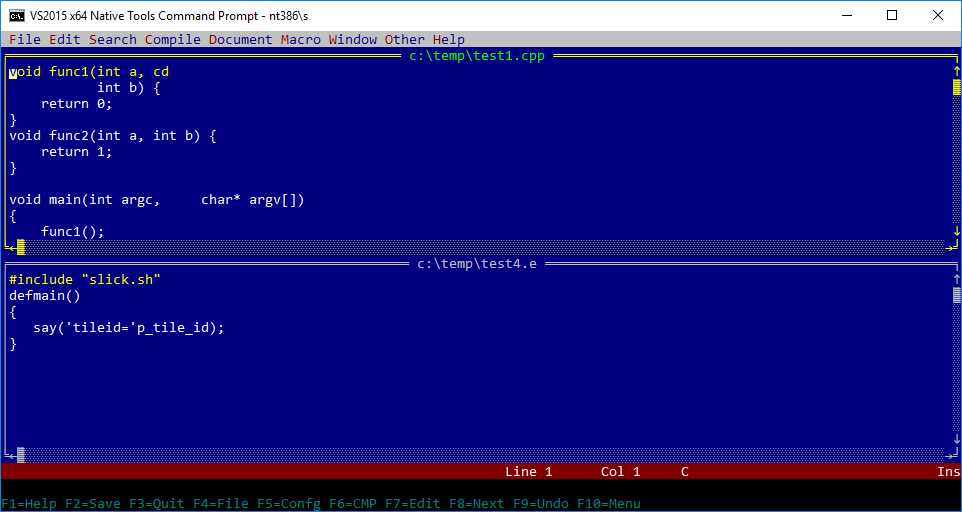
SlickEdit on Windows 10
Last but not least, a new kid on the block, is Micro. It’s a “modern times editor” for all platforms including Windows. It looks really cool and seem to have all recent amenities from editors such as Sublime Text or Atom. Multi windows, syntax highlighting and even it’s own built in terminal emulator for running a subshell. Micro is 100% portable and comes in as a single x64 exe file. It’s 10 MB size but I think well worth keeping around. Unfortunately it doesn’t have built-in file browser. Yes, there is a plugin for it but I don’t know how to use it. Also seems to have issues with Windows style path names. However I’m really happy that a new editor has been developed in recent times. It has a great chance of becoming the missing Windows text mode editor for the future! Definitely worth keeping an eye on it.
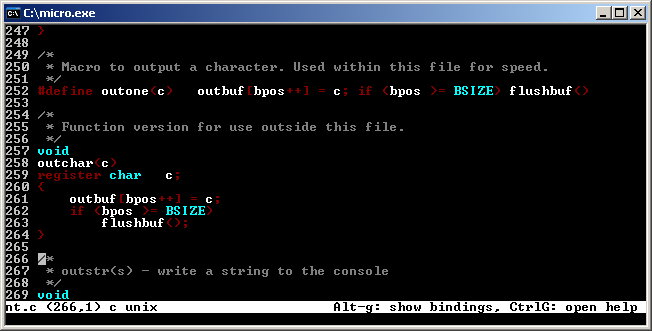
Micro Editor
With this positive news it’s time to wrap up. To summarize there currently is no perfect text mode editor for Windows. I hope that Microsoft can one day step up and provide one. In the mean time I usually stick around to OpenWatcom VI and FAR Manager. For people who do not wish to learn VI, Kinesics KIT may probably be the most perfect editor in short term and Micro in the future. I also hope someone can make a good GNU Nano port using native Win32 APIs without going to pdcurses and cygwin.
Thank you for all suggestions! Have I forgotten or missed any editor? Please let me know and I will promptly add it to the list! Note: please do not include editors that work under Cygwin.
Yori – The Perfect Windows Console Text Editor Has Been Found!
Summary: just perfect, new and well maintained. Works on all Windows editions!
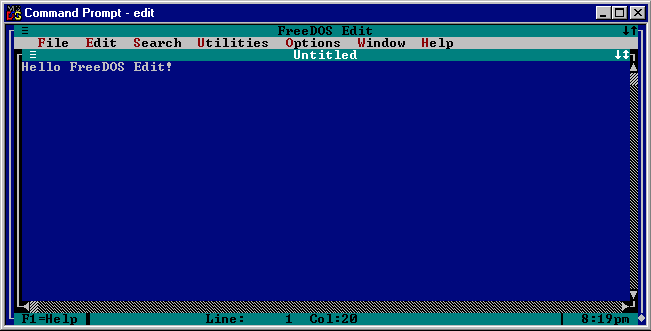
Wendy Krieger recently brought to my attention FreeDOS Edit port to Win32. Overall pretty solid text editor that essentially is edit.com replacement. It’s little dated (2007) however as source code is available it could be freshed up and also build for 64bit and other architectures.
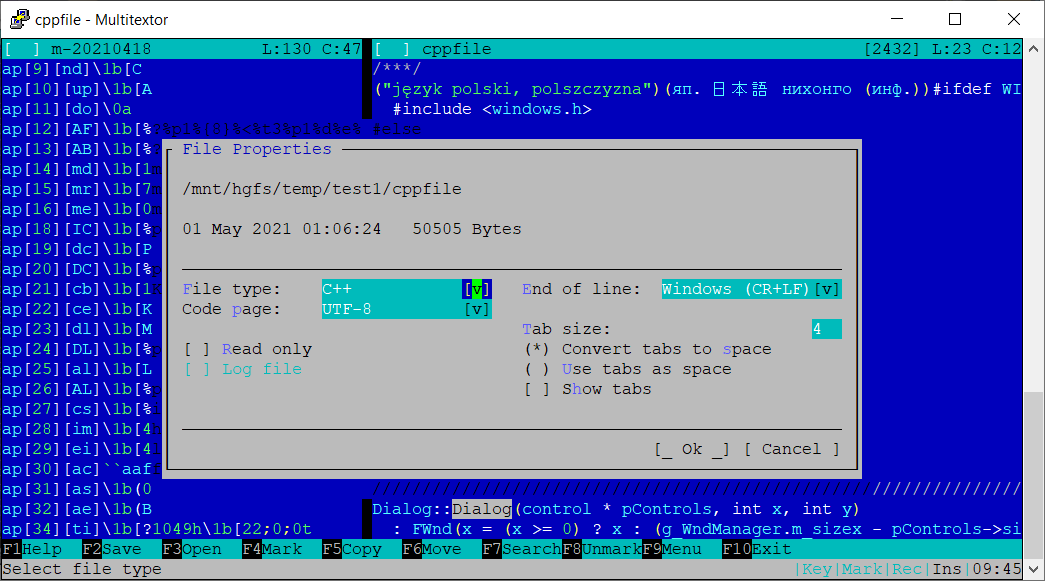
Vikonix sent me his Multitextor editor. The author has rewritten his old text editor to support modern Windows which is pretty cool! A modern from scratch editor is always a good thing! Unfortunately the editor is still beta and not fully released yet. I hope the readers can help Vikonix to beta test and make a release!
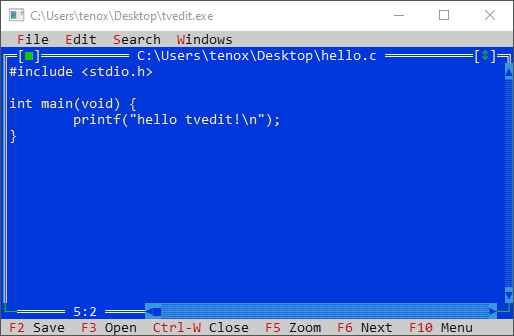
TVedit which is an “example” editor from Tvision, a modern port of the classical Turbo Vision framework. Works on both Windows and DOS. They provide binary releases for x64 Windows here. The editor is an awesome straight forward replacement for edit.com. No configuration options or any features. Just a perfect editing experience! Unfortunately while the editor works pretty well on Windows 10, there are some screen display issues on Windows 7 and it plain doesn’t start on Windows XP. Also worth noting that there is another text editor using Tvision framework called Turbo. It looks like pretty awesome text editor but doesn’t look like it supports Windows at the moment and there are no releases. Maybe in future?
(This is a guest post by xorhash.)
I’ve recently defeated one of my bigger inconveniences, broken DEL as backspace on the UNIX®†operating system, Seventh Edition (commonly known as UNIX V7 or just V7). However, I’ve had another pet peeve for a while: How much manual labor is involved in booting the system. Reader DOS found out that SIMH recently added support for SEND/EXPECT pairs to react to output from the simulator. Think of them like UUCP chat scripts, effectively. This can be used to automate the bootup procedure.
Yet DOS’s script skips over a part of the bootup procedure that can be fully automated with some additional tooling. Namely, setting the date/time to the current time as defined by the host system. As per boot(8), the operator is meant to set the date/time every time the system is brought up. This should be possible to automate, right?
date(1) itself does not support setting years past 2000, so we need custom code in any case. SIMH, fortunately, also provides a way to get the current timestamp in the form of %UTIME%, which is interpreted in any argument to any command. I’ve thus written a utility called tsdate that takes a timestamp as argument and sets the current time to be that timestamp. I put the executable in /etc/tsdate, but there’s really no reason to do so other than not wanting to accidentally call it. Once tsdate is in place, changing DOS’s script slightly will already do the trick:
expect "\n\r# " send "/etc/tsdate %UTIME%\r\004"; c
This approach already has a minor amount of time drift ab initio, namely the difference between the actual time on the host system and the UNIX timestamp. In the worst case, this may be very close to 1. If for some reason you need higher accuracy than this, you’ll probably have a fairly hard time. I could imagine some kind of NTP-over-serial, but you’d need support for chat scripts to get past the authentication due to getty(8) spawning login(1).
The system is not suitable for usage past the year 2038. However, you can at least push it back until around 2100 by changing the internal representation of time to be an unsigned long instead of simply a long. time_t was not used systematically. Instead, everything assumed long as the type for times. This assumption is in a lot of places in userspace and even the man pages use long instead of time_t.
If you overflow tsdate’s timestamp, you’ll just get whatever happens when atol(3) overflows. There’s nothing in the standard library for parsing strings into unsigned long and the year 2038 is far enough away that I didn’t want to bother. stime(2) would presumably also need to be adjusted.
V7 is surprisingly good at handling years past 2000. Most utilities can print years up to and including 2099 properly. Macros for nroff(1)/troff(1), however, are blissfully unaware that years past 1999 may exist. This causes man pages to be supposedly printed in the year 19118. The root cause for this is that the number register yr only holds the current year minus 1900. Patches to the -ms and -man macros are required. Similarly, refer(1) only considers years until 2000 to be actual years, though I did not bother patching that since it should only affect keyword matching.
Leap year handling is broken in two different places due to wrong leap year handling: at(1) and the undocumented dysize() function, used by date(1) as well as inside /usr/src/libc/gen/ctime.c for various purposes. This affects the standard library, so recompiling the entire userland is recommended. Because the calculation is just a naïve division by four, it actually works on the year 2000 itself. A year is a leap year, i.e. has February 29, if a year is:
Leap seconds are also not accounted for, but that comes to nobody’s surprise. Leap seconds just add a second 60 to the usual 00-59, so they don’t hurt doing date calculations on timestamps unless precisely on a leap second. For my purposes, they can be ignored.
Note that I haven’t gone through the system with a fine-toothed comb. There can always be more subtle time/date issues remaining in the system. For my purposes, this works well enough. If other things crop up, you’re welcome to put them in the comments for future generations.
There’s really not much to it. Applying diff and recompilation of the affected parts is left as an exercise for the reader.
Files:
† UNIX is a trademark of The Open Group.