No really, Good old Games, is now doing movies. Â Of course they are somewhat gamer oriented, but I don’t see the infamous Super Mario Bros. movie..
Movies!

No really, Good old Games, is now doing movies. Â Of course they are somewhat gamer oriented, but I don’t see the infamous Super Mario Bros. movie..
Movies!
(note this is a guest post by Tenox)
In previous posts from ASV series I have explained why I got hooked on Atari System V UNIX and what I had to do to get a decent resolution out of Atari TT. Having built the VGA monitor adapter, the next challenge was to replace the internal SCSI hard disk with a flash storage of some sort. I really don’t like spinning hard disks and especial the old ones.
I have mentioned that there are two surviving ASV disk images. The better one was made out of a rather large old, loud and obnoxious Maxtor. I’m definitely not having this monstrosity inside of my beloved Atari!

Maxtor LXT340SY
So how can you replace an old SCSI hard disk with a modern flash device? There actually are several different ways.
If you have the money you can go industrial route, which is a SCSI disk replacement for various machinery and embedded systems produced by ReactiveData. You can buy one of these for a little over $1000 USD. The good part is that they substitute a specific real hard disk model and are exceptionally good in quality of emulation. However, spending a lot of money on my TT and TenoxVGA already, this really wasn’t an option without getting a divorce.
Another approach is to use SCSI to IDE bridge combined with IDE to CF adapter or possibly SCSI to SATA bridge and SATA SSD disk. These are widely used by Atari / Amiga / Mac 68k community. The most popular bridge come from a company called Acard. I actually had one of these at hand, AEC-7220U which I used for TOS/GEM work.

acard front
Did it work? As you can guess – of course it didn’t! The initial boot loader errors out unable to read disk capacity.
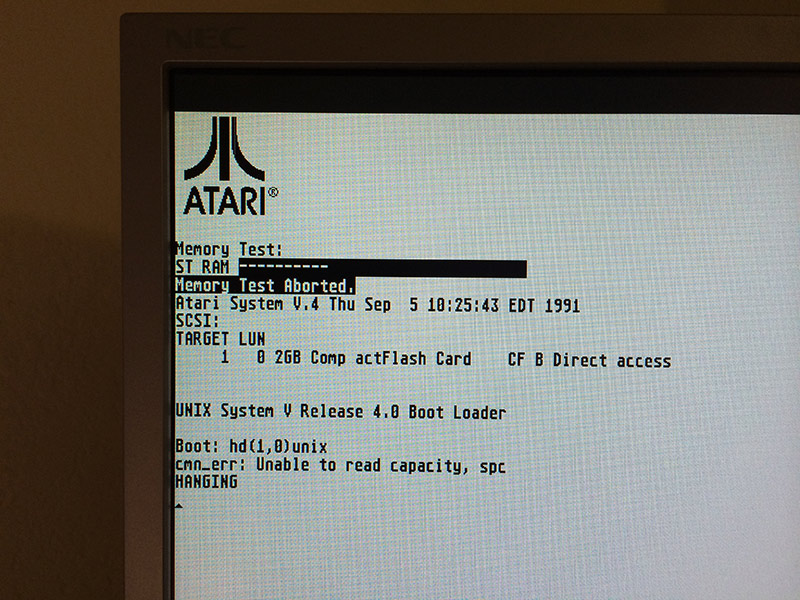
Atari SYS V failed to boot
Atari ST/TT, somewhat similarly to 68k Macs require a hard disk driver, present on the hard disk itself. There are several 3rd party implementations, some of them, like HDDRIVER maintained up to present date. Unfortunately these drivers are TOS specific and obviously don’t work with Atari Unix. The system comes with it’s own hard disk driver which seems to be obsolete and with limited hardware support.
The next step was to research and try out some other SCSI to IDE bridges in hope one would just work. And surprisingly there are several to choose from.
The second on the line was I-O Data R-IDSC21-E/R. No longer produced and supported, however still fairly popular. Usually regarded as the ultimate bridge with most fancy options bells and whistles. It has most jumpers and modes of all tested devices. For instance ATA PIO and DMA modes. Unfortunately this didn’t help at all and same error was observed.

idsc21e
Another device tried was Yamaha v769970. This bridge was conceived to allow use IDE CDROM and Hard Disks with Yamaha samplers. No longer produced and obsolete, it’s somewhat most easy to set up, robust and stable. It’s actually my favorite bridge for day to day use, except for ASV where it just doesn’t work.

v769970
More recent kid on the block is an integrated SCSI2IDE + IDE2CF in one device called Aztec Monster. Recently designed and currently produced in Japan (you can buy one on eBay) is a fairly decent choice, which I recommend to every one. I had a lot of luck with these, except for ASV of course…

CF_AM_r1_1
I also looked in to SCSI to SATA bridges, like this one, but they have additional issues, like need to convert LVD to SE on one end and SATA to IDE to CF on the other. Little bit too complex for what I wanted.
Being out of luck I started researching if it would be possible to build an open source version, which can be easily diagnosed and fixed. Doing so I found out that there in fact is one open source SCSI adapter called SCSI2SD.

SCSI2SD_V3.0_plain
I was bit skeptical in the beginning but then I though that being open source it can be debugged and fixed if it needs to be. So I immediately ordered one.
Once it arrived, I plugged it in, applied the image to the card and BAM! It worked! The system booted fully and worked flawlessly!
Atari Unix System V – Boot Sequence from Antoni Sawicki on Vimeo.
Over time SCSI2SD proven stable and flawless. One feature that Mac users will appreciate:
--apple Set the vendor, product ID and revision fields to simulate an
apple-suppled disk. Provides support for the Apple Drive Setup
utility.
In the next article I will write about my first steps in the system post boot and then bringing it to a more or less usable state. Stay tuned!
for spam.
yay.
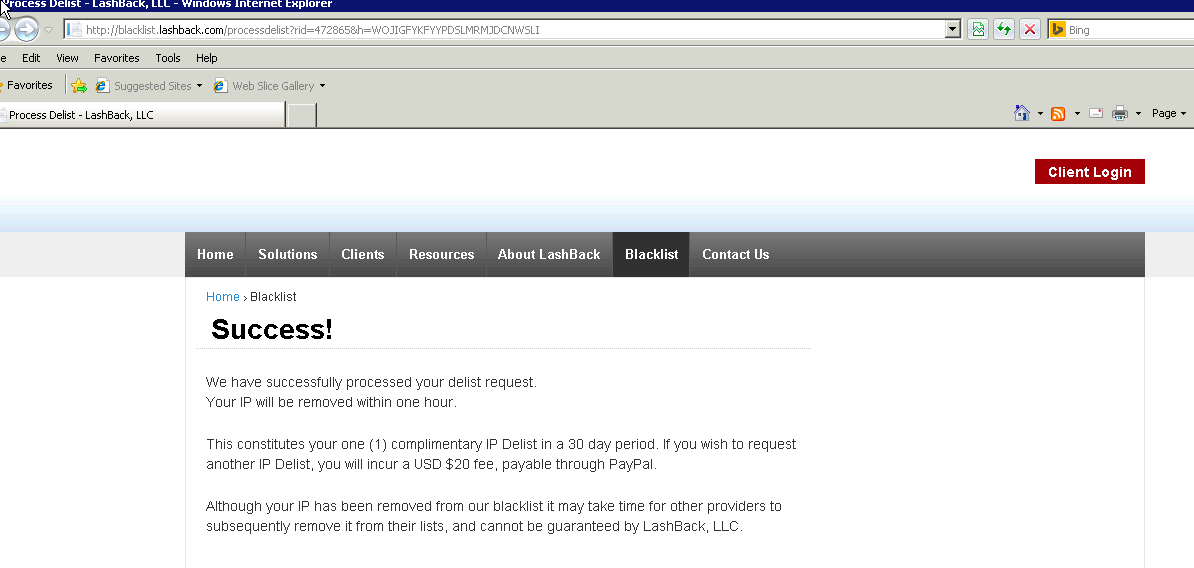
$20 USD ransom
And this is what the internet has become, gone are the days of open connected system, but instead tolls to be paid to trolls as idiots believe their services are legit.
I always thought things would fall apart in censorship (which sure happens), lawyers, and idiotic patents, but I never thought of arbitrary tolls from no name, fly by night companies like this “lashback.com”.
What really amazes me, is that they actually want to demand a $20 ransom for me being able to send email, and I foolishly gave them (and verified) my email address, so without a doubt I’ll see my SPAM volume increase drastically.  So the joke is if you tried to move away from google, you are unable to do so as these NSA friendly companies will no doubt do their best to keep you stuck.
Obviously I got into the wrong business, as people are scared of the big bad internet, and there is money to be made by ‘allowing’ open protocols to function.
(this is a guest post by Tenox)
I’m pretty good at finding bugs in Windows and I get a new one every couple of weeks or so. Today I found out this unbelievable gem:
So there is this (cmd.exe) command called timeout. It works roughly similar to sleep(1) under Unix. It is supposed to stop execution of a batch script for a given period of time. Example:
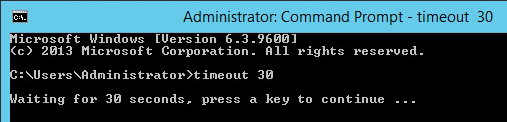 In reality just wishful thinking, because apparently this is not always the case. Sometimes it does and sometimes… it doesn’t.
In reality just wishful thinking, because apparently this is not always the case. Sometimes it does and sometimes… it doesn’t.
Wait… what?
Sounds unbelievable but it appears the timeout command uses Real Time Clock for it’s sleep function. If you change the clock while timeout is running…
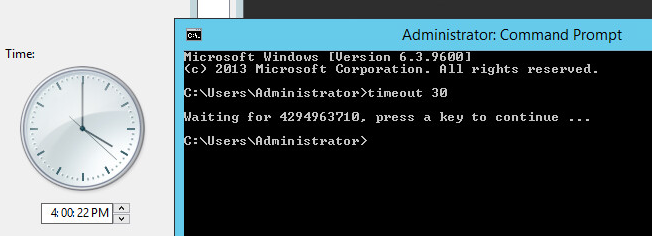 LOL 🙂
LOL 🙂
I found this because my batch scripts were stuck for rather long time when a machine would have time changed by NTP. If the change was negative the timeout command would wait x thousand seconds. When the change was positive the integer rolled and timeout stopped immediately causing avalanche of problems.
So beware to timeout eating your batch scripts…
I found minuszerodegrees simply looking for the IBM 5170 technical reference manual. Â Amazingly it’s online now!
And there is a bunch of other things in there, like the 5150, and the sound blaster manual.
All kinds of old EGA cards, some ATI VGA cards as well.
I’m not to happy with my solution, but it’ll suffice for now.
So every day, I have cron fetch me a new password from makeagoodpassword.com,  update some httpassword entry, and use PHP for a simple redirect.
So let’s say I wan to get neko for the i386, the link was http://vpsland.superglobalmegacorp.com/install/WindowsNT4.0-i386/games/neko98-i386.7z Now when you click on the link you get a 404 looking page that has a link to the new directory structure, and includes the username & password (I’m not currently evil enough to generate a random user, but I may have to do that in the future…).
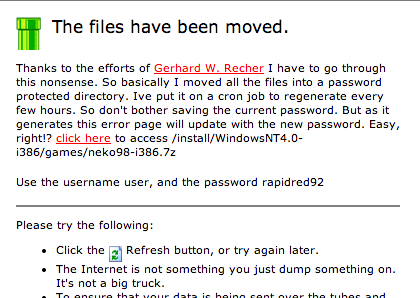
Click the click here link!
So the new path lives in the /old directory making the new location of neko98Â http://vpsland.superglobalmegacorp.com/old/install/WindowsNT4.0-i386/games/neko98-i386.7z
So use the username/password combo on the page, and you’ll be good to go.
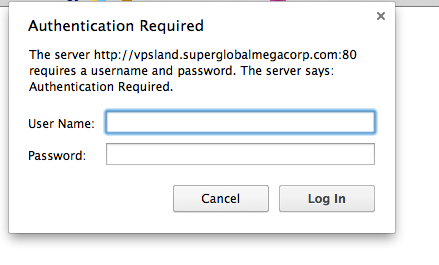
For example user/rapidred92
Sorry about all this.
So apparently it’s all the news, The best selling series, Game of Thrones was written using Wordstar 4. Â On a dedicated MS-DOS computer of all things.
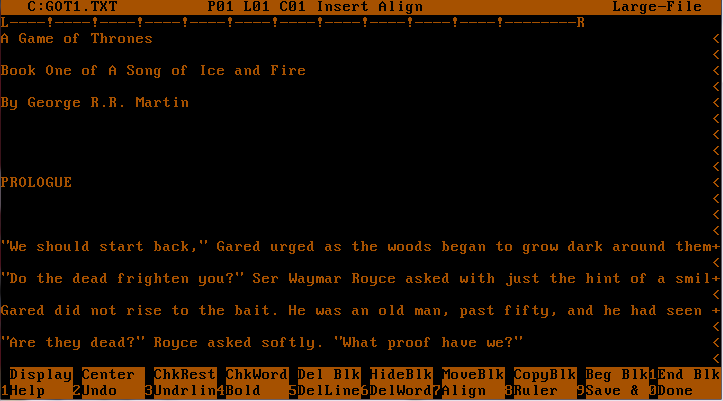
What George probably sees..
Well isn’t that kinda cool.
As he says, he likes Wordstar because it doesn’t try to think for him, and he likes MS-DOS because there is no distractions.
“I actually like it, it does everything I want a word processing program to do and it doesn’t do anything else,†Martin told Conan O’Brien. “I don’t want any help. I hate some of these modern systems where you type a lower case letter and it becomes a capital letter. I don’t want a capital. If I wanted a capital, I would have typed a capital. I know how to work the shift key.â€
He best says it back in 2007:
I do my writing on a completely different computer than the one I use for email and the internet, in part to guard against viruses, worms, and nightmares like this. My work machine does not even use Windows (which I loathe). I write with WordStar 4.0 on a pure DOS-based machine. Mock if you must… but WordStar and DOS are both stable as rocks, and never give me the sort of headaches I get from Windows. (I won’t even talk about Microsoft Word, about which I have nothing printable to say).
For anyone chasing Wordstar nostalgia, you can leaf through the manual.
Following up my JunOS post, here is a handy script I cooked up to pull the configuration from a Cisco IOS device. Â The one trip up for this stuff is sometimes you can logon to a cisco device, and you can be at the enabled state, you may have to enable, Â and depending on how it’s configured you may have to use an enable password, which may be your password (again) or you may have to use a different password.
So yeah with a bunch of testing around this seems to work well enough for me.
#!/usr/local/bin/expect —
set MYUSER “my_user_name”
set MYPASS “my_password”
set ENPASS “my_enable_password”
set HOST [lindex $argv 0];
set timeout 90
if {$argc!=1} {
puts “Usage is scritpname <ip address>\r”
exit 1
}
#
#
puts “Connecting to $HOST\r”
spawn ssh $HOST -l $MYUSER
# Deal with hosts we’ve never talked to before
# or just logon
#
expect {
“*yes/no*” {send “yes\r” ; exp_continue }
“*assword:” {send “${MYPASS}\r” }
}
set ALREADY 0
expect {
“\r*>” {}
“\r*#” { set ALREADY 1}
“*enied” {exit 1}
“*assword” {exit 1}
}
if { $ALREADY < 1 } {
send “enable\r”
expect “*assword:” {
send “${MYPASS}\r”
expect {
“*enied” {
send “enable\r”
expect “*assword:”
send “${ENPASS}\r”
expect {
“*enied” {
exit 1}
“\r*#” {}
}
}
“\r*#” {}
}
}
}
send “show run\r”
expect {
“ore” {send ” “; exp_continue}
“\r*#” {}
}
#Let’s get out of here
send “q\r”
expect eof
exit 0
This is a little more cleaner than the prior JunOS one, as I’ll keep on improving it.
It works with ASA’s (tested 8.2)and IOS (tested 12.2)
I’ll add more as I go along, but the first annoying thing was that there was no ‘central’ repository of configs. Â Now call me old fashioned, but I liked the old days when telnet was scriptable and I could go and talk to my Cisco stuff.. but here we are in 2014, and I suppose I should break down and use that ‘expect’ package I’ve heard so much about.
So I have this Linux host that I want to talk to all these hosts.  The first problem is that it being a new host it hasn’t talked to anything so it doesn’t know the private keys.  Annoying.  The other thing is that some commands like to initiate a pager, which takes time to slap the space bar.  It’s much better to have the computer do it.
#!/usr/local/bin/expect —
set MYUSER “my_user_id”
set MYPASS “my_password”
set HOST [lindex $argv 0];
if {$argc!=1} {
puts “Usage is scritpname  <ip address>\r”
exit 1
}
puts “Connecting to $HOST\r”
spawn ssh $HOST -l $MYUSER
# Deal with hosts we’ve never talked to before
# or just login
#
expect {
“continue connecting (yes/no)?”
{send “yes\r”
expect “password:”
send “$MYPASS\r”
}
# We’ve been here before
“password:”
{send “$MYPASS\r”}
}
# Some commands run from configure, some don’t.
# It may be easier to just enter configure mode
expect “> ”
send “configure\r”
expect “# ”
#
# Pick a command to run
send “run show arp no-resolve\r”
#send “save terminal\r”
#send “run show lldp neighbors\r”
#
# Deal with paging. I don’t want to make any
# changes at *ALL* to the device, so instead
# I deal with the pager
#
expect {
“more” {send ” “; exp_continue}
“# ” {send “exit\r”}
}
# We are done, get out of here!
#
expect “>”
send “exit\r”
So in this shell example I’ve set it up to recognize that it’s never established before. Â I know it’s messy that it has the password 2x I guess I could do variable substitution if I was more scripty but right now I just want to get some basic things in/out of the routers all the time, such as port status, MAC’s and I want it like yesterday.
The important part of the ‘more’ bypass is the exp_continue keyword. Â Which took a lot of googling around because everyone “expects more”. Â It’s kind of annoying when your keywords are common English words.
And as you can see, this is a good enough base for doing some more complicated things. Â Of course I wouldn’t roll changes out automatically, but for the adventurous there you go. Â It wouldn’t take much to adapt this for Cisco stuff, as the CLI operates more or less the same.
The real fun begins with parsing all this stuff.
fragready’s ticketing system.
So yeah, I’m still without my “dedicated” server, Â and now even fragready’s portal is broken. Â I just want to get on the box, and do a secure wipe myself.
So at least I have this super discount VM in Germany to keep my blog running. Â Before I was hosting Exchange on KVM in the dedicated server. Â However now I’m going to pull all my crap back home, as I setup an OpenVPN connection from my home to the VPS, and from there got some static routing working well enough that I can host an Exchange server at home, and use postfix to store & forward. Â A pretty simple & standard setup.
Well I got to update my MX records, and what do I get?
websitespot
Now the people I bought my domain names from, websitespot.com is down. Â Even “Down for everyone or just me” has them down.
I swear, I can’t catch a break on this one.