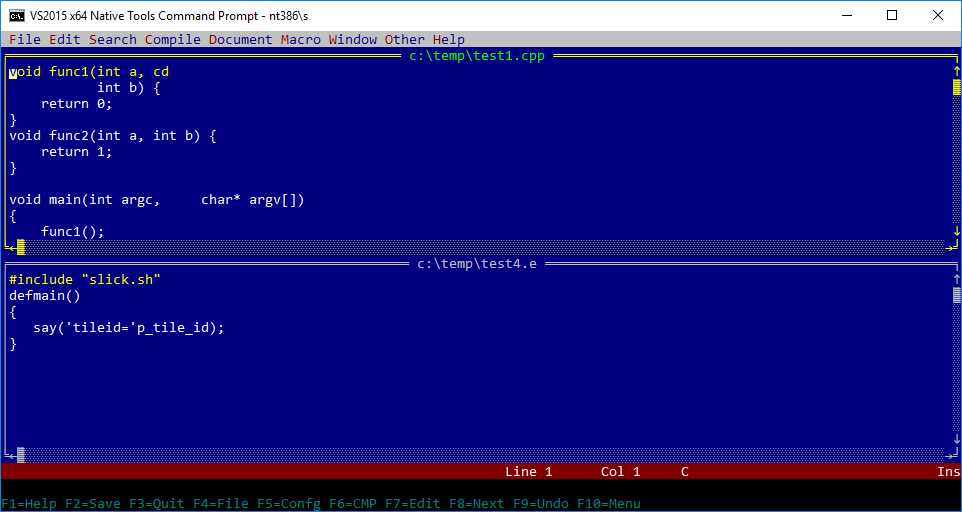
Latest Visual Studio updates now bring official ARM/ARM64 support for Desktop Apps, little hidden, but here is how to enable it.
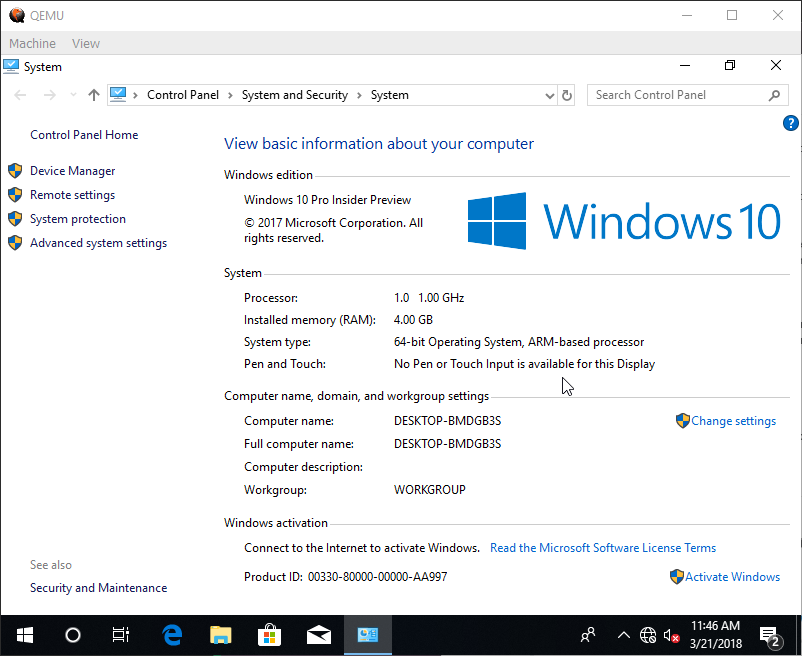
Being able to compile Windows ARM apps, I wanted to try to actually run them, but … on what exactly? There are some developer evaluation boards. Apparently someone managed to run it on Raspberry PI. Most importantly however you can run Windows 10 ARM64 on QEMU. This is some serious Fun With Virtualization!
Windows 10 ARM64 running on QEMU
I’m not claiming to be the first. Clever people have already done it. I just wanted to make it little easier for the lazier of us. Here is how.
Follow the link above but skip the shady UUP business in step #3 and download ready made iso instead. You can google the iso image from windows.cmd and it will take you to this link. You need the rest of the files like UEFI firmware and virtio drivers.
For the even more impatient here is a ready to run image with Windows pre-installed. Because QEMU now comes with DLL HELL I’m not including it in the archive. You will have to install it separately.
If you want to transfer files in/out of the image a tip from Pete Batard of Rufus:
Create a folder named say “transfer” and add the following option to the launch script:
-hdb fat:rw:transfer
This will create a second FAT32 formatted disk, that maps your transfer\
directory to the QEMU virtual machine. In our case, Windows 10 will see it
and make it automatically accessible as “QEMU VVFAT (D:)”. You can even
use this to write file from the VM to the host (though, depending on how
fast Windows flushes its disk cache, they may take a while to appear).
Go have fun and port some apps to ARM64 with free community edition of Visual Studio. I’m going to start with Aclock 🙂
(This is a guest post by Antoni Sawicki aka Tenox)
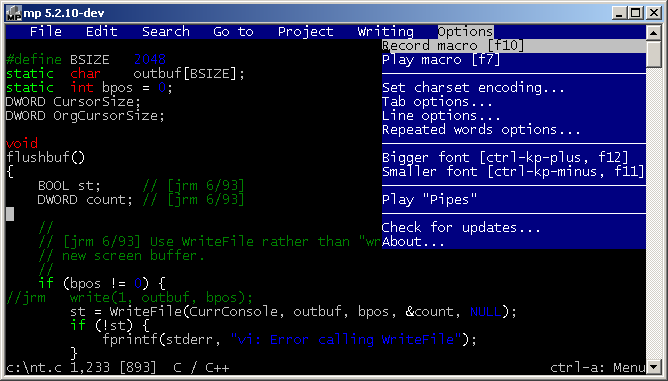
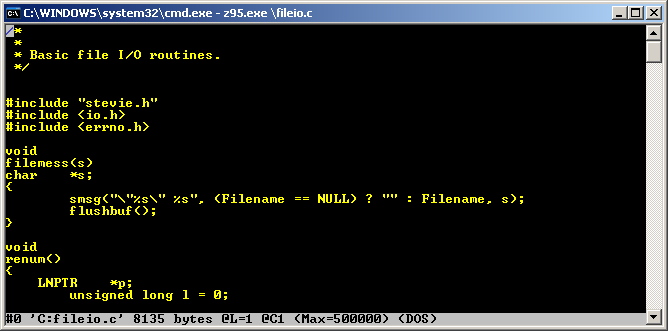
In a recent blog post Wanted: Console Text Editor for Windows I lamented about lack of a good console/cmd/PowerShell text editor for Windows. When researching for the article I made rather interesting discovery. There in a fact has been a native Windows, 32bit, console based text editor. It was available since earliest days of NT or even before. But let’s start from…
…in the beginning there was Z editor. Developed by Steve Wood for TOPS-20 operating system in 1981. Some time after that, Steve sold the source code to Microsoft, which was then ported to MS-DOS by Mark Zbikowski (aka the MZ guy) to become the M editor.
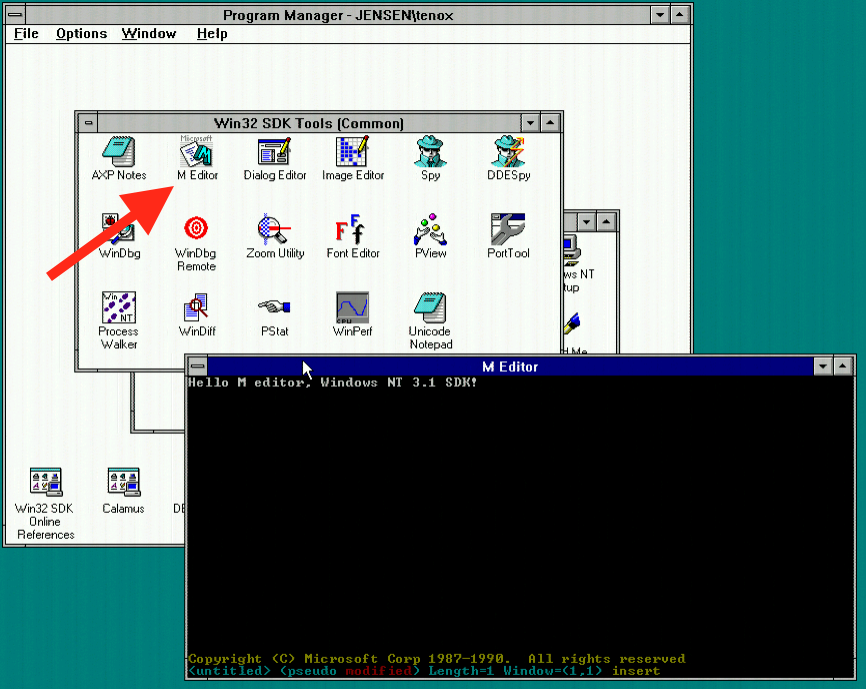
M editor
The DOS-based M editor was included and sold as part of Microsoft C 5.1 (March 1988), together with the OS/2 variant, the MEP editor (perhaps M Editor Protected-mode). The official name of M/MEP was simply Microsoft Editor. The same editor was also available earlier (mid-1987) as part of the MS OS/2 SDK under a different name: SDKED. Note that normally SDKED insists in operating in full screen mode. Michal Necasek generously spent his time and patched it up so that it can be run in windowed mode for your viewing pleasure.
SDKED on OS/2
However my primary interest lies with Windows NT. The NT Design Workbook mentions that in the early days a self-hosting developer workstation included compiler, some command line tools and a text editor – MEP. Leaked Windows NT builds sometimes include IDW, Internal Development Workstation, which also seem to contain a variant of the same editor. In fact some these tools including MEP.EXE can be found on Windows NT pre-release CD-ROMs (late 1991) under MSTOOLS. It was available for both MIPS and 386 as a Win32 native console based application.
MEP on Windows NT Pre-Release
The editor was later also available for Alpha, i386, MIPS, and PowerPC processors on various official Windows NT SDKs from 3.1 to 4.0. It survived up to July 2000 to be last included in Windows 2000 Platform SDK.
M editor from NT SDK 3.1 running on Alpha AXP
MEP from NT SDK on Windows NT 4.0
The Win32 version of MEP also comes with an icon and a file description which calls it M Editor in NT 3.1 SDK and later Microsoft Extensible Editor.
From time perspective, it was rather unfortunate that this gem was buried in the SDK rather than being included on Windows NT release media. However I can understand that the editor wasn’t very user friendly or intuitive, compared to say edit.com from MS-DOS. It came from a different era and similar to VI or Emacs, didn’t have “PC user friendly” key bindings or menus.
But that’s not the end of the story. The editor of many names survives to this day, at least unofficially. If you dig hard enough you can find it on OpenNT 4.5 build. For convenience, this and other builds including DOS M, OS/2 MEP and SDKED, NT SDK MEP can be downloaded here.
Digging through the archive I found not one but two copies of the editor code, lurking in the source tree. One under the name MEP inside \private\utils\mep\ folder and a second copy under name Z (which was the original editor for TOPS) in\private\sdktools\z folder. MEP was included in Platform SDK, while Z was only available as part of IDW.
Doing a few diffs I was able to get some insight on the differences. Looks like MEP was initially ported from OS/2 to NT and bears some signs of being an OS/2 app. The Z editor on the other hand is a few years newer and has many improvements and bug fixes over MEP. It also uses some specific NT only features.
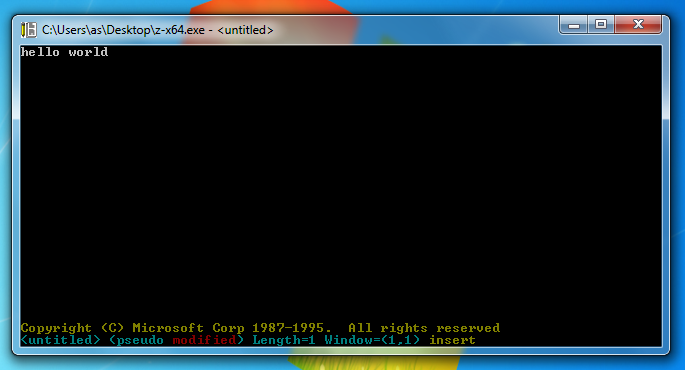
Sadly the internal Z editor was never released anywhere outside of Redmond. All the versions outlined so far had copyrights only up to 1990, while Z clearly has copyright from 1995. Being a few years newer and more native to NT I wanted to see if a build could be made. With some effort I was able to separate it from the original source tree and compile stand alone. Being a pretty clean source code I was able to compile it for all NT hardware platforms, including x64, which runs comfortably on Windows 10. You can download Z editor for Windows here.
Z editor on flashy Windows 7 x64
But how do you even use this thing?
Platform SDK contains pretty solid documentation in tools.chm.
Here is a handy cheat sheet:
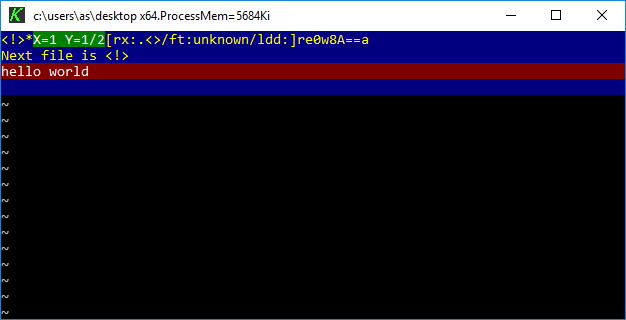
Last but not least there is a modern open source re-implementation of Z editor named K editor. It’s written from scratch in C++ and LUA and has nothing to do with the original MEP source code. K is built only for x64 using Mingw. There are no ready to run binaries so I made a fork and build.
K editor on Windows 10 x64
The author Kevin Goodwin has kindly included copies of original documentation if you actually want to learn how to use this editor.
Did I say I’m done with UNIX Seventh Edition (V7)? How silly of me; of course I’m not. V7 is easy to study, after all.
Something that’s always bothered me about the stdio.h primitives fread() and fwrite() are their weak guarantees about what they actually do. Is a short read or write “normal†in the sense that I should normally expect it? While this makes no answer about modern-day operating systems, a look at V7 may enlighten me about what the historical precedent is.
As an aside: It’s worth noting that the stdio.h functions are some of the few that require a header. It was common historical practice not to declare functions in headers, just see crypt(3) as an example.
I will first display the man page, then ask the questions I want to answer, then look at the implementation and finally use that gained knowledge to answer the questions.
2. Into the Man Page
The man page for fread() and fwrite() is rather terse. Modern-day man pages for those functions are equally terse, though, so this is not exactly a novelty of age. Here’s what it reads:
Fread reads, into a block beginning at ptr, nitems of data of the type of *ptr from the named input stream. It returns the number of items actually read.
Fwrite appends at most nitems of data of the type of *ptr beginning at ptr to the named output stream. It returns the number of items actually written.
Fread and fwrite return 0 upon end of file or error.
So there are the following edge cases that are interesting:
In fread(): If sizeof(*ptr) is greater than the entire file, what happens?
If sizeof(*ptr) * nitems overflows, what happens?
Is the “number of items actually read/written†guaranteed to be the number of items that can be read/written (until either EOF or I/O error)?
Is the “number of items actually written†guaranteed to have written every item in its entirety?
What qualifies as error?
3. A Look at fread()
Note: All file paths for source code are relative to /usr/src/libc/stdio/ unless noted otherwise. You can read along at the TUHS website.
rdwr.c implements fread(). fread() is simple enough; it’s just a nested loop. The outer loop runs nitems times. The outer loop sets the number of bytes to read (sizeof(*ptr)) and runs the inner loop. The inner loop calls getc() on the input FILE *stream and writes each byte to *ptr until either getc() returns a value less <Â 0 or all bytes have been read.
/usr/include/stdio.h implements getc(FILE *p) as a C preprocessor macro. If there is still data in the buffer, it returns the next character and advances the buffer by one. Interestingly, *(p)->_ptr++&0377 is used to return the character, despite _ptr being a char *. I’m not sure why that &0377 (&0xFF is there. If there is no data in the buffer, it instead returns _filbuf(p).
filbuf.c implements _filbuf(). This function is a lot more complex than the other ones until now. It begins with a check for the _IORW flag and, if set, sets the _IOREAD flag as well. It then checks if _IOREAD is not set or if _IOSTRG is set and returns EOF (defined as -1 in stdio.h) if so. These all seem rather inconsequential to me. I can’t make heads or tails of _IOSTRG, however, but it seems irrelevant; _IOSTRG is only ever set internally in sprintf and sscanf for temporary internal FILE objects. After those two flag checks, _filbuf() allocates a buffer into iop-<_base, which seems to be the base pointer of the buffer. If flag _IONBF is set, which happens when setbuf() is used to switch to unbuffered I/O, a temporary, static buffer is used instead. Then read() is called, requesting either 1 bytes if unbuffered I/O is requested or BUFSIZ bytes. If read() returned 0, the FILE is flagged as end-of-file and EOF is returned by _filbuf(). If read() returned <0, the FILE is flagged as error and EOF is returned by _filbuf(). Otherwise, the first character that has been read is returned by _filbuf() and the buffer pointer incremented by one.
According to its man page, read() only returns 0 on end-of-file. It can also return -1 on “many conditionsâ€, namely “physical I/O errors, bad buffer address, preposterous nbytes, file descriptor not that of an input fileâ€
As an aside, BUFSIZ still exists today. ISO C11 § 7.21.2 no. 9 dictates that BUFSIZ must be at least 256. V7 defines it as 512 in stdio.h. One is inclined to note that on V7, a filesystem block was understood 512 bytes length, so this was presumably chosen for efficient I/O buffering.
4. A Look at fwrite()
rdwr.c also implements fwrite(). fwrite() is effectively the same as fread(), except the inner loop uses putc(). After every inner loop, a call to ferror() is made. If there was indeed an error, the outer loop is stopped.
/usr/include/stdio.h implements putc(int x, FILE *p) as a C preprocessor macro. If there is still room in the buffer, the write happens into the buffer. Otherwise, _flsbuf() is called.
flsbuf.c implements _flsbuf(int c, FILE *iop). This function, too, is more complex than the ones until now, but becomes more obvious after reading _filbuf(). It starts with a check if _IORW is set and if so, it’ll set _IOWRT and clear the EOF flag. Then it branches into two major branches: the _IONBF branch without buffering, which is a straight call to write(), and the other branch, which allocates a buffer if none exists already or otherwise calls write() if the buffer is full. If write() returned less than expected, the error flag is set and EOF returned. Otherwise, it returns the character that was written.
According to its man page, write() returns the number of characters (bytes) actually written; a non-zero value “should be regarded as an errorâ€. With only a cursory glance over the code, this appears to happen for similar reasons as read(), which is either physical I/O error or bad parameters.
5. Conclusions
In fread(): If sizeof(*ptr) is greater than the entire file, what happens?
On this under-read, fread() will end up reading the entire file into the memory at ptr and still return 0. The I/O happens byte-wise via getc(), filling up the buffer until getc() returns EOF. However, it will not return EOF until a read() returns 0 on EOF or -1 on error. This result may be meaningful to the caller.
If sizeof(*ptr) * nitems overflows, what happens?
No overflow can happen because there is no multiplication. Instead, two loops are used, which avoids the overflow issue entirely. (If there are strict filesystem constraints, however, it may be de-facto impossible to read enough bytes that sizeof(*ptr) * nitems overflows. And of course, there’s no way you could have enough RAM on a PDP-11 for the result to actually fit into memory.)
Is the “number of items actually read/written†guaranteed to be the number of items that can be read/written (until either EOF or I/O error)?
Partially: Both fread() and fwrite() short-circuit on error. This causes the number of items that have actually been read or written successfully to be returned. The only relevant error condition is filesystem I/O error. Due to the byte-wise I/O, it’s possible that there was a partial read or write for the last element, however. Therefore, it would be more accurate to say that the “number of items actually read/written†is guaranteed to be the number of non-partial items that can be read/written. A short read or short write is an abnormal condition.
Is the “number of items actually written†guaranteed to have written every item in its entirety?
No, it isn’t. A partial write is possible. If a series of structs is written and then to be read out again, however, this is not a problem: fread() and fwrite() only return the count of full items read or written. Therefore, the partial write will not cause a partial read issue. If a set of bytes is written, this is an issue: There will be incomplete data – possibly to be parsed by the program. It is therefore to preferable to write (and especially read) arrays of structs than to write and read arrays of bytes. (From a modern-day perspective, this is horrendous design because this means data files are not portable across platforms.)
What qualifies as error?
Effectively, only a physical I/O error or a kernel bug. Short fread() or fwrite() return values are abnormal conditions. I’m not sure if there is the possibility that the process got a signal and the current read() or write() ends up writing nothing before the EINTR; this seems to be more of a modern-day problem than something V7 concerned itself.
(This is a guest post by Antoni Sawicki aka Tenox)
Since 2012 or so, Microsoft has been pushing concept of running Windows Server “headless”, without GUI, and administering everything through PowerShell. I remember sitting through countless TechEd / Ignite sessions year after year, and all I could see were blue PowerShell command prompts everywhere. No more wizards, forms, dialogs. MMC and GUI based administration is suddenly thing of a past. Just take a look at Server Core, WinPE, Nano, PS Remoting, Windows SSH server, Recovery Console and Emergency Management Services. Even System Center is a front end for PowerShell. Nowadays everything seems to be text mode.
This overall is good news and great improvement since previous generations of Windows, but what if you need to create or edit a PowerShell, CMD script or some config file?
Oooops, looks like you are screwed. Seems that Redmond forgot to include most crucial tool in sysadmins, or developers job – a simple text mode editor. WTF Microsoft?
So, are there any 3rd party alternatives? Yes, and there are and quite a lot of them! Unfortunately none are perfect and most are old and unmaintained. This article aims to be a grand tour of whatever is available out there.
Note that throughout the article I will be repeatedly referring to a “portable” editor. For me this means a single .exe file, that can be carried around on a USB pen drive or network share. I also cry a lot about 64-bit Windows builds because I work a lot in WinPE and other environments where syswow64 is not available.
First lets start with most obvious choices, well known through years. If you search for a Windows Console Editor VIMand Emacswill naturally pop up first. These editors don’t need any introduction or praising. I use VIM every day and Emacs every now and then. These two had ports to Windows for as long as I can remember and in terms of quality and stability definitely up top. The problem is that both are completely foreign and just plain unusable to a “typical Windows user”. The learning curve of weird key controls is pretty steep. Also portability suffers a lot, at least for Emacs. Both editors come with hundreds of supporting files and are massive in size. Emacs.exe binary is whopping 83 MB in size and the zip file contains two of them just in case. Whole unpacked folder is 400 MB. WTF.
Emacs on Windows Console
VIM is fortunately much much better you can extract single vim.exe binary from the package and use it without much complaints:
VIM on Windows Console
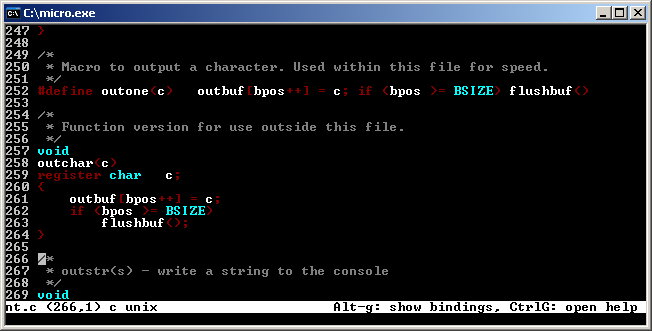
When talking about about VI and Emacs hard not to mention some more historical versions. Emacs’ little brother MicroEmacs has been available for Windows since earliest days. I’m not going to attempt to link to any particular one since there are so many flavors.
MicroEmacs
VIM little brother VI also comes in different shapes and forms. Lets take look at a few.
Stevie is a very special case. Rumor has it, this editor played crucial role in development of Windows NT itself and has been included since earliest days of NT as part of the Internal Developer Workstation. Because it was ported by folks at Redmond the quality should be pretty good. Unfortunately README states “this is an incomplete VI that has not been fully tested. Use at your own risk.”. For a historical note according to Wikipedia, Stevie port to Amiga has been used by Bram Moolenaar as a base source code for VIM.
Stevie for Windows aka NT VI, part of Internal Developer Workstation
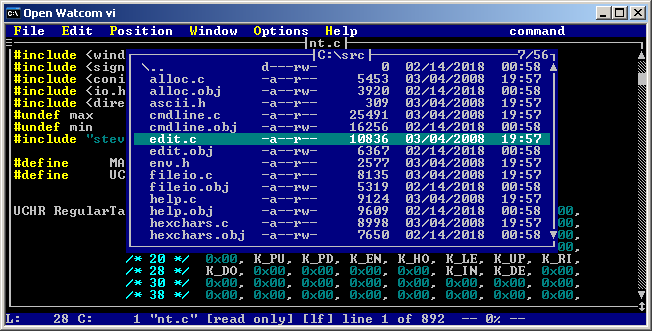
One particularly interesting case is VI editor from Watcom compiler suite. It has very nice TUI known from MS-DOS editors, syntax highlighting and online help. One of nicest versions of VI available for Windows. Small portable and just all around handy editor. This is probably my main to go text editor when working on WinPE or Server Core. Unfortunately not very well known. I hope it can gain some popularity it deserves.
OpenWatcom VI Editor
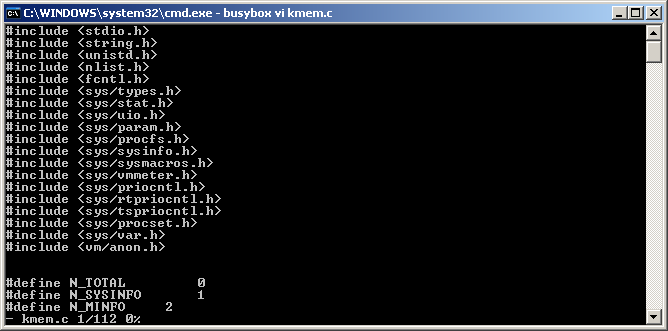
Thanks to Federico Bianchi just learned that there is a BusbyBox port to Windows having both 32bit and 64bit builds, 100% portable as just a single exe file! Most importantly it contains a working vi editor that understands window resizing and Win32 paths. I’m going to be keeping this one around. Awesome job Busybox! As a last thought I wish they also included Nano.
BusyBox Win32 VI Editor
I don’t want this article to be all about VI and Emacs clones. Let this nice color menus be a segue to more native Windows / DOS editors at least departing from hardcore keystrokes and Unix.
For a change in theme lets look at SemWare TSE Pro, the editor that originally started as QEDIT for DOS and OS/2. It has most advanced features one could ever imagine for a text mode editor. Including resizable windows, hex editor, macros and spell checker. I really wish I could use it in everyday’s life. Unfortunately TSE has some drawbacks, it lacks portable version and install is little cumbersome. Currently no x64 build but the author is working on it. TSE is not free, the license is $45 but it allows to install on as many machines as you need. UPDATE: TSE is now Freeware!
SemWare TSE Pro
Next one up is Brief. It used to be very popular in it’s own time and sparked quite bit of following as there are numerous of editors being “brief style”. It’s a nice and small console based text editor. It comes in two versions basic (free) and professional (paid). The pro version supports splitting in to multiple windows regexp and unicode. Unfortunately it runs at $120 per user and there is no 64bit build or a portable edition.
Brief
There also is an open source clone of Brief called GRIEF. Flipping through the manual it has very impressive set of features including $120 windowing feature and macros. Unfortunately it’s rather unportable due to large amount of dll and other files. 64bit build could probably be made if someone wanted.
GRIEF free Brief Clone
As we talk about less costly options there is Kinesics Text Editor aka KIT. It’s more well known if you search on google, completely free and after installing you can find and a x64 binary file! This makes it somewhat portable and able to run in WinPE for instance. Until recently the editor did not have 64bit version so I did not have chance to use it much in practice but the TUI appears to have a well rounded easy to use (F1 or right mouse click brings menus). It does’t seem to have any advanced features but it’s very stable and actively maintained. And frankly this is what matters for editing on the console. It may actually be the right missing Windows console editor.
Kinesics aka KIT
Another one is Minimum Profit. It’s fully open source and it supports a lot of platforms in both windowing and text mode. It has a lot of interesting features such as syntax highlighting, spell checked and menus. It can’t be easily made portable as it needs a lot of files of it’s own scripting language. I also find that screen refresh is somewhat funky. UPDATE: 64bit version now available!
Minimum Profit
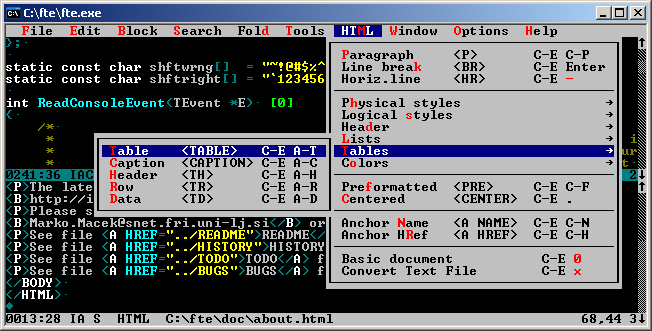
Lets look at somewhat well known FTE. It’s a very nice text editor available on many platforms such QNX, OS/2 and of course Windows. It has nice TUI, split windows, syntax highlighting, folding, bookmarks and tools for HTML authoring etc. Overall awesome editor falling short only to TSE. Support for NT console has been available since 1997. I have recently fixed couple of bugs and built a 64bit portable version.
FTE Editor
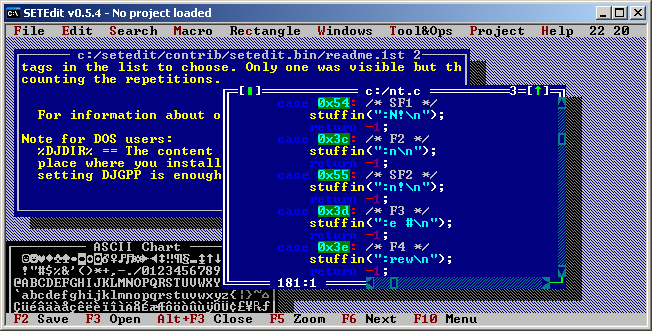
One could also not forget Borland Turbo C IDE. Apparently there is an open source clone of the IDE as a regular editor called SETEdit. It’s multi platform editor with MS-DOS style windows and menus. Syntax highlighting macros and all regular amenities. Looks like DOS version can play MP3 songs while you code. There is a native WinNT build made with BCPP. To run on Windows you install the DOS version then overwrite dos exe file win NT exe. The editor is absolutely awesome, unfortunately currently doesn’t work in a portable manner and there is no x64 binary. However as it’s open source it could be probably made.
SETEdit a Borland Turbo C IDE Clone
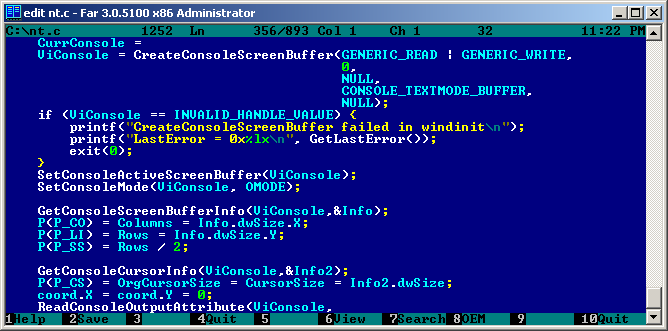
When talking about MS-DOS style windows, Norton Commander like file managers come to mind. There is one particular built specifically for Windows – FAR Manager. Written by author of WinRAR, originally shareware, but since 2007 it has been released under BSD license. FAR does come with a built in text editor hence it’s featured here. It’s actively supported and developed, and because it’s designed from ground up for Windows, it’s probably most stable and trustworthy of all applications in this post. I normally don’t use it that much, but I do keep a copy of it lying around when I need to do some more heavy lifting from Windows console. There is a 64bit binary by default but unfortunately FAR can be hardly made portable as it comes with 400 files.
FAR Manager Text Editor
When talking about Norton Commander clones lets not forget Midnight Commander, which does have an unofficial native Windows console build called mcwin32. Similar to FAR, MC has a very nice built-in text editor. MC overall seems far nicer than FAR but because it’s multi platform rather than WIndows specific and not officially supported I don’t trust it as much for day to day use.
GNU Midnight Commander
When on topic of Unix, lets talk about GNU Nano. In it’s native habitat, it’s very popular and stable editor making it a perfect choice for a text mode console. Unfortunately Windows port is lacking quite a lot, especially for things like resizing Window or handling file names. The official build looks like a fusion of cygwin, mingw, pdcurses and other horrible stuff. Version that comes with Mingw/MSYS is not portable and so far I failed in attempts to build a static windows binary by hand. Nano predecessor UW Pico unfortunately never did have console terminal Windows port. Authors of Pine decided to make it semi graphical application with it’s own window, menus and buttons. Sad story for both Pico and Nano. Hopefully one day someone will make a 100% native Windows port.
Another non-vi and non-emacs Unix editor with Windows console port is JED. Frankly I have not used JED that much in the past although I did play with it in the 90s. This is the original web page of Jed editor. It does seem to have menus and multi windows. Unfortunately doesn’t look like it can be easily made in to a portable image.
JED Win32 Port
Yet another more obscure editor is ED-NT which is DEC EDT clone. Unfortunately seems to be completely dead an unmaintained. Sources are still available through archive.org so perhaps it could be still looked after if someone wanted EDT editor on Windows.
ED-NT
When going through obscurities via archive.org one can also mention ZABED and more specifically Z95 which is a 32bit console version. I don’t know anything about the editor and I’m little too lazy to play with it extensively although pdf manual is available. Probably little too old and too obscure for every day use.
Z95
Perhaps even more obscure to a mere mortal is The Hessling Editor aka THE. It’s based on VM/CMS editor XEDIT. I did briefly use VM/CMS and XEDIT in early ’90 but I never liked it so much. THE comes in as a native Win32 binary. Not easily portable as it requires some additional files. Also no 64bit binary but source code is available.
THE aka The Hessling Editor
Thanks to Andreas Kohl I have learned about X2 Programmers Editor which also has NT console version. The editor seems very nice and has extensive help, syntax highlighting, etc. Unfortunately I have never used this editor before. Last version has been released in 2008 which is not loo long ago but sadly there has been no update since. I hope the author will continue to maintain it.
X2 Programmers Editor
Andreas also brought up Personal Editor, which comes as PE32 and PE64. Looks like really well maintained and stable editor designed and developed specifically for Windows. 64bit bit version is really cool however the editor doesn’t seem to be portable and $40 license will probably prevent me from using it professionally in environments where I would need it. Never the less looks like a very fine editor!
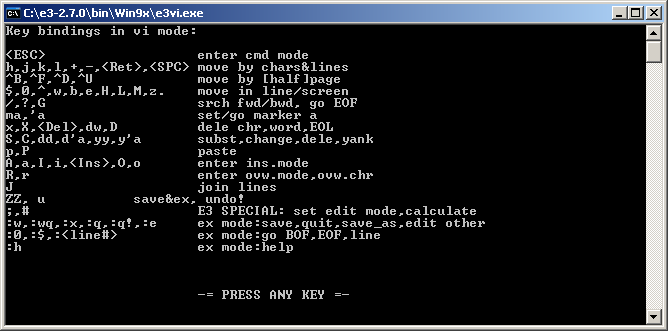
Another find is e3 editor. Pretty interesting stuff. It’s written in assembler and available on many operating systems including DOS and Windows. Looks like it’s still maintained as last version was released in 2016. It supports multiple modes, Wordstar, Emacs, Vi, Pico and Nedit by renaming or linking the main executable. It’s definitely portable as it doesn’t need any extra files and the exe is just 20KB (take that emacs!). Unfortunately because of assembler I don’t think there will be a 64bit release any time soon. Overall seem to be really cool to keep this one around.
e3 editor
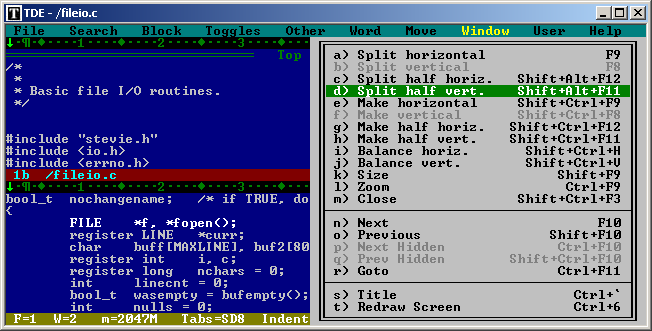
A really cool last minute find is public domain TDE – Thomson-Davis Editor. Released not so long ago in 2007 it has 16, 32bit DOS and 32bit Windows console executable. It has DOS style menus,syntax highlighting, resizable windows and bunch of other features. Looks like a very handy editor. I don’t know how did I miss it. Since source code was available so I was able to make a x64 build. This is really untested so use at your own risk!
TDE
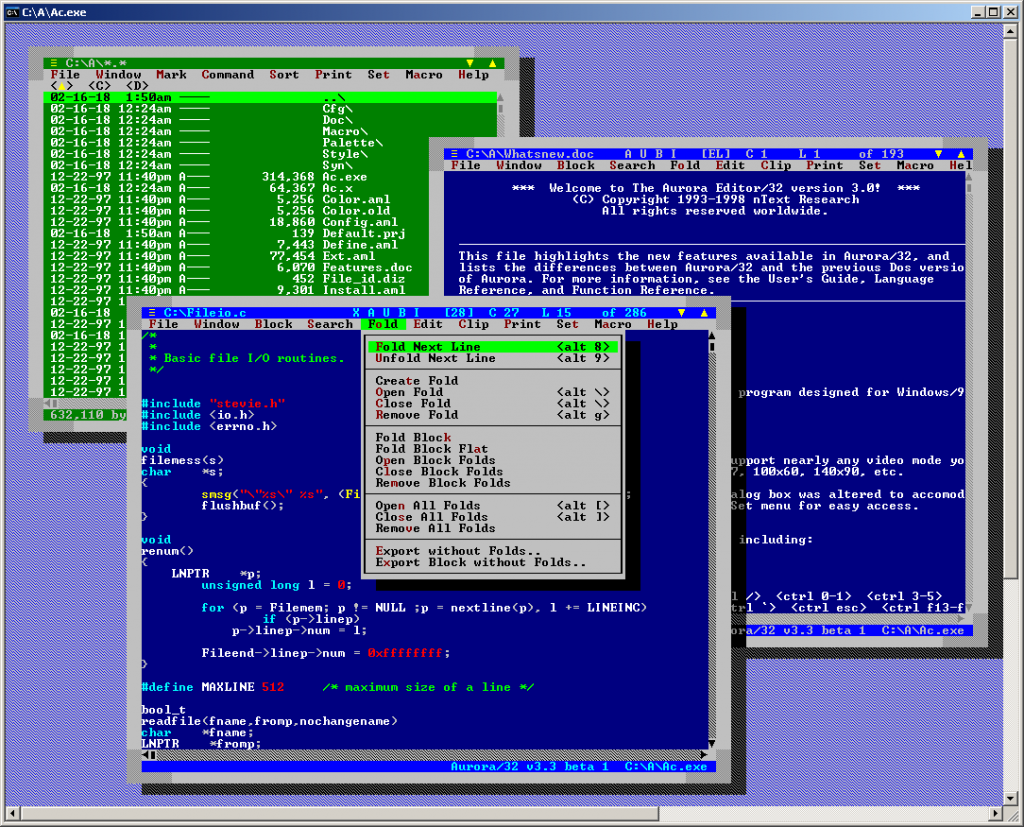
Also a recent find – shareware editor called Aurora. I never had a chance to use it in the past but after taking it for a quick spin I fell in love. The text mode UI it feels like it’s own windowing operating system! Originally for DOS, Unix and OS/2, Win32 port is relatively new. Unfortunately it’s no longer maintained or even sold. This is very sad because the editor is extremely cool. I hope the author may be willing to release the source code so it could be maintained.
Aurora
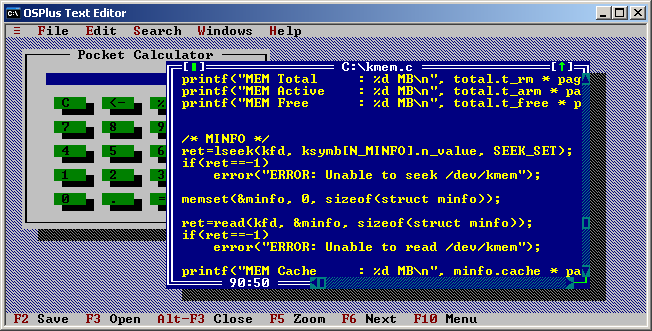
Thanks to Richard Wells I have learned about OSPlus Text Editor. It’s a really cool little editor with Borland style TUI and multi windows. It doesn’t seem to have any advanced features but it does have a built in calculator and allows background play of WAV and MID. Also allows format conversion of various formats like Word, Write or RTF in to text using Microsoft Office converters. Pretty cool if you need to read Word based documentation on the text console. Sadly looks like the application is no longer maintained. I guess with little bit of luck a 64bit version could be compiled using Mingw64 or MSVC.
OSPlus Text Editor
Also recently learned about HT. This is more intended as a binary/exe/hex editor and analyzer. However it seems to have an excellent plain text editor with HTML and C syntax highlighting. It doesn’t have very advanced features but one that stands out is a very detailed change log, much like Photoshop History. It shows you what exactly has been changed and in what order. This is pretty cool when doing heavy editing of some important files. The latest version is from 2015 and it’s 100% portable single exe. Unfortunately no x64 but I guess it should be easy enough to build one with Mingw64.
HT
Just in, freshly “re-discovered” – Microsoft Editor. This editor is a Win32 port of Mark Zbikowski’s port of Z editor to MS-DOS. It has been widely used with Microsoft C as M, MEP and and OS/2 SDK as SDKED. Shockingly looks like Windows NT did actually have a console mode text editor since it’s earliest days or even earlier. Included in Windows NT pre-release CDs and later on the official Windows NT/2000 SDKs, hiding in plain sight, was a Win32 console mode MEP.EXE. Only if Microsoft included this editor with Windows itself the world would be a different place. I have recently dug it out of SDK and made available here. There also are additional builds (including x64) here. There is a dedicated blog post about it.
Microsoft Editor aka MEP aka Z
As with many commercial editors there is an open source edition of Z named K_Edit. It is a modern re-implementation from scratch written in C++ and LUA. It builds only on 64bit Windows and there probably is no chance for any other version. As of today author of K doesn’t provide ready binaries but I was able to make one myself.
K editor on Windows 10 x64
Reader brdlph pointed me to a pretty fresh editor named Textadept. It’s a cross platform, both GUI and TUI editor. Windows console version uses Curses, but it performs remarkably well. It has a look and feel of a modern programmer’s text editor with syntax highlighting, line numbers, etc. The zip archive comes with over 400 files so it’s rather not portable. Also there seem to be no Windows 64bit build although there is one for Linux. The application seem to be very well maintained and the latest release is from January 2018!
Textadept
Reader Andreas Kohl mentioned SlickEdit, which was a text mode editor for DOS, OS/2 and Windows console (before Visual SlickEdit stole it’s name). According to the company’s employee an OS/2 version of the editor was used by some Windows NT team members to develop their operating system. In early days, SlickEdit CTO traveled to Redmond to port the application to a barely yet functioning NT console system so that the developers could use native dev environment. SlickEdit was most likely the very fist commercial application for Windows NT. It was available in 386, Alpha, MIPS and PowerPC editions. I’m hoping to obtain old evaluation copies. So far I was able to get this screenshot:
SlickEdit on Windows 10
Last but not least, a new kid on the block, is Micro. It’s a “modern times editor” for all platforms including Windows. It looks really cool and seem to have all recent amenities from editors such as Sublime Text or Atom. Multi windows, syntax highlighting and even it’s own built in terminal emulator for running a subshell. Micro is 100% portable and comes in as a single x64 exe file. It’s 10 MB size but I think well worth keeping around. Unfortunately it doesn’t have built-in file browser. Yes, there is a plugin for it but I don’t know how to use it. Also seems to have issues with Windows style path names. However I’m really happy that a new editor has been developed in recent times. It has a great chance of becoming the missing Windows text mode editor for the future! Definitely worth keeping an eye on it.
Micro Editor
With this positive news it’s time to wrap up. To summarize there currently is no perfect text mode editor for Windows. I hope that Microsoft can one day step up and provide one. In the mean time I usually stick around to OpenWatcom VI and FAR Manager. For people who do not wish to learn VI, Kinesics KIT may probably be the most perfect editor in short term and Micro in the future. I also hope someone can make a good GNU Nano port using native Win32 APIs without going to pdcurses and cygwin.
Thank you for all suggestions! Have I forgotten or missed any editor? Please let me know and I will promptly add it to the list! Note: please do not include editors that work under Cygwin.
Summary: just perfect, new and well maintained. Works on all Windows editions!
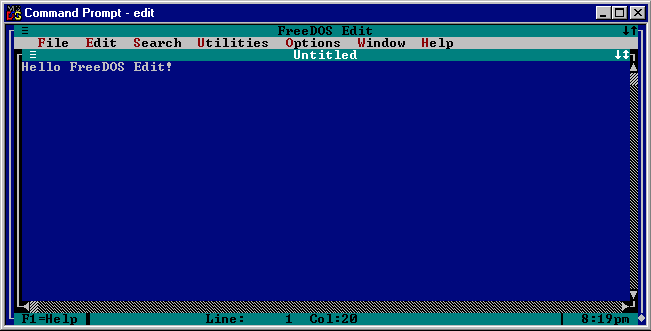
Wendy Krieger recently brought to my attention FreeDOS Edit port to Win32. Overall pretty solid text editor that essentially is edit.com replacement. It’s little dated (2007) however as source code is available it could be freshed up and also build for 64bit and other architectures.
FreeDOS Editor port to Win32
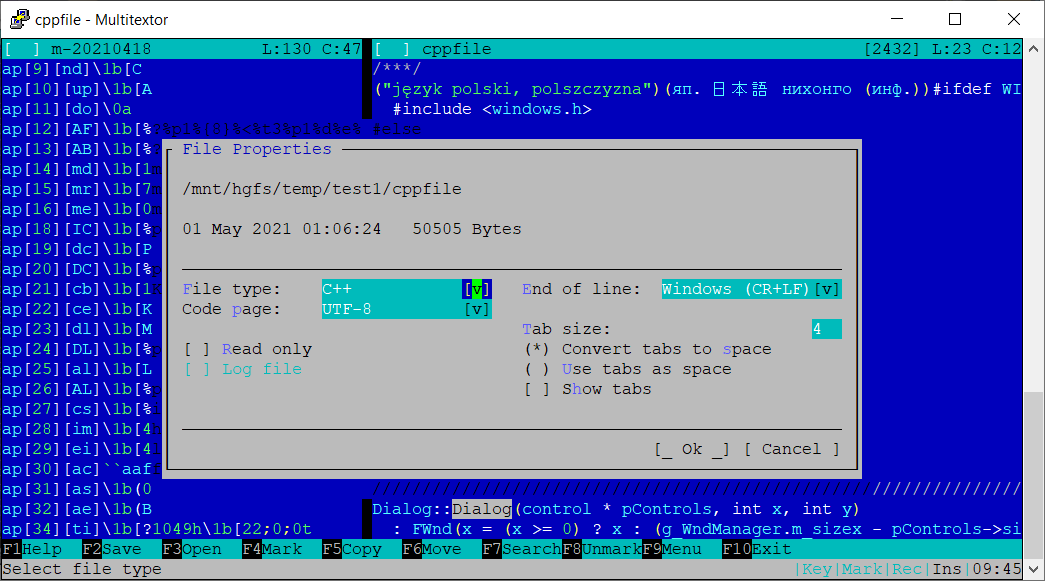
Vikonix sent me his Multitextor editor. The author has rewritten his old text editor to support modern Windows which is pretty cool! A modern from scratch editor is always a good thing! Unfortunately the editor is still beta and not fully released yet. I hope the readers can help Vikonix to beta test and make a release!
Multitextor editor
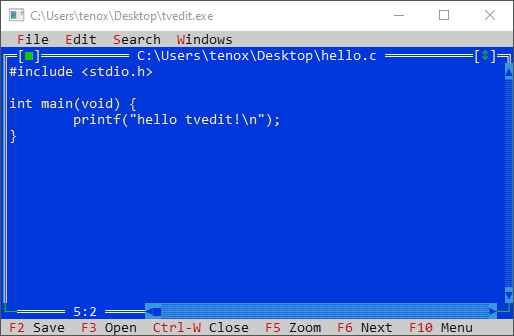
TVedit which is an “example” editor from Tvision, a modern port of the classical Turbo Vision framework. Works on both Windows and DOS. They provide binary releases for x64 Windows here. The editor is an awesome straight forward replacement for edit.com. No configuration options or any features. Just a perfect editing experience! Unfortunately while the editor works pretty well on Windows 10, there are some screen display issues on Windows 7 and it plain doesn’t start on Windows XP. Also worth noting that there is another text editor using Tvision framework called Turbo. It looks like pretty awesome text editor but doesn’t look like it supports Windows at the moment and there are no releases. Maybe in future?
I’ve recently defeated one of my bigger inconveniences, broken DEL as backspace on the UNIX®†operating system, Seventh Edition (commonly known as UNIX V7 or just V7). However, I’ve had another pet peeve for a while: How much manual labor is involved in booting the system. Reader DOS found out that SIMH recently added support for SEND/EXPECT pairs to react to output from the simulator. Think of them like UUCP chat scripts, effectively. This can be used to automate the bootup procedure.
Yet DOS’s script skips over a part of the bootup procedure that can be fully automated with some additional tooling. Namely, setting the date/time to the current time as defined by the host system. As per boot(8), the operator is meant to set the date/time every time the system is brought up. This should be possible to automate, right?
Setting the Date Automatically
date(1) itself does not support setting years past 2000, so we need custom code in any case. SIMH, fortunately, also provides a way to get the current timestamp in the form of %UTIME%, which is interpreted in any argument to any command. I’ve thus written a utility called tsdate that takes a timestamp as argument and sets the current time to be that timestamp. I put the executable in /etc/tsdate, but there’s really no reason to do so other than not wanting to accidentally call it. Once tsdate is in place, changing DOS’s script slightly will already do the trick:
expect "\n\r# " send "/etc/tsdate %UTIME%\r\004"; c
This approach already has a minor amount of time drift ab initio, namely the difference between the actual time on the host system and the UNIX timestamp. In the worst case, this may be very close to 1. If for some reason you need higher accuracy than this, you’ll probably have a fairly hard time. I could imagine some kind of NTP-over-serial, but you’d need support for chat scripts to get past the authentication due to getty(8) spawning login(1).
The system is not suitable for usage past the year 2038. However, you can at least push it back until around 2100 by changing the internal representation of time to be an unsigned long instead of simply a long. time_t was not used systematically. Instead, everything assumed long as the type for times. This assumption is in a lot of places in userspace and even the man pages use long instead of time_t.
If you overflow tsdate’s timestamp, you’ll just get whatever happens when atol(3) overflows. There’s nothing in the standard library for parsing strings into unsigned long and the year 2038 is far enough away that I didn’t want to bother. stime(2) would presumably also need to be adjusted.
Year 2000 Compatibility in the System
V7 is surprisingly good at handling years past 2000. Most utilities can print years up to and including 2099 properly. Macros for nroff(1)/troff(1), however, are blissfully unaware that years past 1999 may exist. This causes man pages to be supposedly printed in the year 19118. The root cause for this is that the number register yr only holds the current year minus 1900. Patches to the -ms and -man macros are required. Similarly, refer(1) only considers years until 2000 to be actual years, though I did not bother patching that since it should only affect keyword matching.
Leap year handling is broken in two different places due to wrong leap year handling: at(1) and the undocumented dysize() function, used by date(1) as well as inside /usr/src/libc/gen/ctime.c for various purposes. This affects the standard library, so recompiling the entire userland is recommended. Because the calculation is just a naïve division by four, it actually works on the year 2000 itself. A year is a leap year, i.e. has February 29, if a year is:
a multiple of 4, and
not a multiple of 100, or
a multiple of 400.
Leap seconds are also not accounted for, but that comes to nobody’s surprise. Leap seconds just add a second 60 to the usual 00-59, so they don’t hurt doing date calculations on timestamps unless precisely on a leap second. For my purposes, they can be ignored.
Note that I haven’t gone through the system with a fine-toothed comb. There can always be more subtle time/date issues remaining in the system. For my purposes, this works well enough. If other things crop up, you’re welcome to put them in the comments for future generations.
The Good Stuff
There’s really not much to it. Applying diff and recompilation of the affected parts is left as an exercise for the reader.
I have been messing with the UNIX®† operating system, Seventh Edition (commonly known as UNIX V7 or just V7) for a while now. V7 dates from 1979, so it’s about 40 years old at this point. The last post was on V7/x86, but since I’ve run into various issues with it, I moved on to a proper installation of V7 on SIMH. The Internet has some really good resources on installing V7 in SIMH. Thus, I set out on my own journey on installing and using V7 a while ago, but that was remarkably uneventful.
One convenience that I have been dearly missing since the switch from V7/x86 is a functioning backspace key. There seem to be multiple different definitions of backspace:
BS, as in ASCII character 8 (010, 0x08, also represented as ^H), and
DEL, as in ASCII character 127 (0177, 0x7F, also represented as ^?).
V7 does not accept either for input by default. Instead, # is used as the erase character and @ is used as the kill character. These defaults have been there since UNIX V1. In fact, they have been “there” since Multics, where they got chosen seemingly arbitrarily. The erase character erases the character before it. The kill character kills (deletes) the whole line. For example, “ba##gooo#d” would be interpreted as “good” and “bad line@good line” would be interpreted as “good line”.
There is some debate on whether BS or DEL is the correct character for terminals to send when the user presses the backspace key. However, most programs have settled on DEL today. tmux forces DEL, even if the terminal emulator sends BS, so simply changing my terminal to send BS was not an option. The change from the defaults outlined here to today’s modern-day defaults occurred between 4.1BSD and 4.2BSD. enf on Hacker News has written a nice overview of the various conventions.
Changing the Defaults
These defaults can be overridden, however. Any character can be set as erase or kill character using stty(1). It accepts the caret notation, so that ^U stands for ctrl-u. Today’s defaults (and my goal) are:
Function
Character
erase
DEL (^?)
kill
^U
I wanted to change the defaults. Fortunately, stty(1) allows changing them. The caret notation represents ctrl as ^. The effect of holding ctrl and typing a character is bitwise-ANDing it with 037 (0x1F) as implemented in /usr/src/cmd/stty.c and mentioned in the stty(1) man page, so the notation as understood by stty(1) for ^? is broken for DEL: ASCII ? bitwise-AND 037 is US (unit separator), so ^? requires special handling. stty(1) in V7 does not know about this special case. Because of this, a separate program – or a change to stty(1) – is required to call stty(2) and change the erase character to DEL. Changing the kill character was easy enough, however:
$ stty kill '^U'
So I wrote that program and found out that DEL still didn’t work as expected, though ^U did. # stopped working as erase character, so something certainly did change. This is because in V7, DEL is the interrupt character. Today, the interrupt character is ^C.
Clearly, I needed to change the interrupt character. But how? Given that stty(1) nor the underlying syscall stty(2) seemed to let me change it, I looked at the code for tty(4) in /usr/sys/dev/tty.c and /usr/sys/h/tty.h. And in the header file, lo and behold:
I assumed just changing these defaults would fix the defaults system-wide, which I found preferable to a solution in .profile anyway. Changed the header, one cycle of make all, make unix, cp unix /unix and a reboot later, the system exhibited the same behavior. No change to the default erase, kill or interrupt characters. I double-checked /usr/sys/dev/tty.c, and it indeed copied the characters from the header. Something, somewhere must be overwriting my new defaults.
Studying the man pages in vol. 1 of the manual, I found that on multi-user boot init calls /etc/rc, then calls getty(8), which then calls login(1), which ultimately spawns the shell. /etc/rc didn’t do anything interesting related to the console or ttys, so the culprit must be either getty(8) or login(1). As it turns out, both of them are the culprits!
getty(8) changes the erase character to #, the kill character to @ and the struct tchars to { '\177', '\034', '\021', '\023', '\004', '\377' }. At this point, I realized that:
there’s a struct tchars,
it can be changed from userland.
The first member of struct tchars is char t_intrc, the interrupt character. So I could’ve had a much easier solution by writing some code to change the struct tchars, if only I’d actually read the manual. I’m too far in to just settle with a .profile solution and a custom executable, though. Besides, I still couldn’t actually fix my typos at the login prompt unless I make a broader change. I’d have noticed the first point if only I’d actually read the man page for tty(4). Oops.
login(1) changes the erase character to # and the kill character to @. At least the shell leaves them alone. Seriously, three places to set these defaults is crazy.
Fixing the Characters
The plan was simple, namely, perform the following substitution:
Function
Old Character
Old Character
ASCII (Octal)
New Character
New Character
ASCII (Octal)
erase
#
043
DEL
0177
kill
@
0100
^U
025
interrupt
DEL
0177
^C
003
So, I changed the characters in tty(4), getty(8) and login(1). It worked! Almost. Now DEL did indeed erase. However, there was no feedback for it. When I typed DEL, the cursor would stay where it is.
Pondering the code for tty(4) again, I found that there is a variable called partab, which determines delays and what kind of special handling to apply if any. In particular, BS has an entry whose handler looks like this:
/* backspace */
case 2:
if (*colp)
(*colp)--;
break;
Naïve as I was, I just changed the entry for DEL from “non-printing” to “backspace”, hoping that would help. Another recompilation cycle and reboot later, nothing changed. DEL still only silently erased. So I changed the handler for another character, recompiled, rebooted. Nothing changed. Again. At that point, I noticed something else must have been up.
I found out that the tty is in so-called echo mode. That means that all characters typed get echoed back to the tty. It just so happens that the representation of DEL is actually none at all. Thus it only looked like nothing changed, while the character was actually properly echoed back. However, when temporarily changing the erase character to BS (^H) and typing ^H manually, I would get the erase effect and the cursor moved back by one character on screen. When changing the erase character to something else like # and typing ^H manually, I would get no erasure, but the cursor moved back by one character on screen anyway. I now properly got the separation of character effect and representation on screen. Because of this unprintable-ness of DEL, I needed to add a special case for it in ttyoutput():
What this does is first send a BS to move the cursor back by one, then send a space to rub out the previous character on screen and then send another BS to get to the previous cursor position. Fortunately, my terminal lives in a world where doing this is instantaneous.
Getting the Diff
For future generations as well as myself when I inevitably majorly break this installation of V7, I wanted to make a diff. However, my V7 is installed in SIMH. I am not a very intelligent man, I didn’t keep backup copies of the files I’d changed. Getting data out of this emulated machine is an exercise in frustration.
Transmission over ethernet is out by virtue of there being no ethernet in V7. I could simulate a tape drive and write a tar file to it, but neither did I find any tools to convert from simulated tape drive to raw data, nor did I feel like writing my own. I could simulate a line printer, but neither did V7 ship with the LP11 driver (apparently by mistake), nor did I feel like copy/pasting a long lpr program in – a simple cat(1) to /dev/lp would just generate fairly garbled output. I could simulate another hard drive, but even if I format it, nothing could read the ancient file system anyway, except maybe mount_v7fs(8) on NetBSD. Though setting up NetBSD for the sole purpose of mounting another virtual machine’s hard drive sounds silly enough that I might do it in the future.
While V7 does ship with uucp(1), it requires a device to communicate through. It seems that communication over a tty is possible V7-side, but in my case, quite difficult. I use the version of SIMH as packaged on Debian because I’m a lazy person. For some reason, the DZ11 terminal emulator was removed from that package. The DUP11 bit synchronous interface, which I hope is the same as the DU-11 mentioned /usr/sys/du.c, was not part of SIMH at the time of packaging. V7 only speaks the g protocol (see Ptbl in /usr/src/cmd/uucp/cntrl.c), which requires the connection to be 8-bit clean. Even if the simulator for a DZ11 were packaged, it would most likely be unsuitable because telnet isn’t 8-bit clean by default and I’m not sure if the DZ11 driver can negotiate 8-bit clean Telnet. That aside, I’m not sure if Taylor UUCP for Linux would be able to handle “impure” TCP communications over the simulated interface, rather than a direct connection to another instance of Taylor UUCP. Then there is the issue of general compatibility between the two systems. As reader DOS pointed out, there seem to be quite some difficulties. Those difficulties were experienced on V7/x86, however. I’m not ruling out that the issues encountered are specific to V7/x86. In any case, UUCP is an adventure for another time. I expect it’ll be such a mess that it’ll deserve its own post.
In the end, I printed everything on screen using cat(1) and copied that out. Then I performed a manual diff against the original source code tree because tabs got converted to spaces in the process. Then I applied the changes to clean copies that did have the tabs. And finally, I actually invoked diff(1).
Closing Thoughts
Figuring all this out took me a few days. Penetrating how the system is put together was surprisingly fairly hard at first, but then the difficulty curve eased up. It was an interesting exercise in some kind of “reverse engineering” and I definitely learned something about tty handling. I was, however, not pleased with using ed(1), even if I do know the basics. vi(1) is a blessing that I did not appreciate enough until recently. Had I also been unable to access recursive grep(1) on my host and scroll through the code, I would’ve probably given up. Writing UNIX under those kinds of editing conditions is an amazing feat. I have nothing but the greatest respect for software developers of those days.
Here’s the diff, but V7 predates patch(1), so you’ll be stuck manually applying it: backspace.diff
ChuckMcM on Hacker News (https://news.ycombinator.com/item?id=15990351) reacted to my previous entry here about trying to typeset old troff sources with groff. It was said that ‘‘you really can’t appreciate troff (and runoff and scribe) unless you do all of your document preparation on a fixed width font 24 line by 80 column terminal’’.
‘‘Challenge accepted’’ I said to myself. However, it would be quite boring to just do my document preparation in this kind of situation. Thus, I raised the ante: I will do my document preparation on a fixed width font 24 line by 80 column terminal on an ancient UNIX . That document is the one you are reading here.
2. Getting an old version of UNIX
While it would have been interesting to run my experiment on SIMH with a genuine UNIX , I was feeling far too lazy for that. Another constraint I made for myself is that I wanted to use the Internet as little as possible. Past the installation phase, only resources that are on the filesystem or part of the Seventh Edition Manual should be consulted. However, if I have to work with SIMH, chances are I’d be possibly fighting the emulator and the old emulated hardware much more than the software.
2.1. FreeBSD 1.0
My first thought was that I could just go for FreeBSD 1.0 or something. FreeBSD 1.0 dates from around 1993. That was surprisingly recent, but I needed a way to get the data off this thing again, so I did want networking. As luck would have it, FreeBSD 1.0 refused to install, giving me a hard read error when trying to read the floppy. FreeBSD 2.0 was from 1995 and already had colorful menus to install itself (!). That’s no use for an exercise in masochism.
2.2. V7/x86
I turned to browsing http://gunkies.org/wiki/Main_Page for a bit, hoping to find something to work with. Lo and behold, it pointed me to http://www.nordier.com/v7x86/! V7/x86 is a port of UNIX version 7 to the x86. It made some changes to V7, among those are:
1.
including the more pager,
2.
including the vi editor,
3.
providing a console for the screen, rather than expecting a teletype, and
4.
including an installation script.
The version of vi that ships with it is surprisingly usable, even by today’s standards. I believe I would’ve gone mad if I’d had to use ed to write this text with.
3. Installing V7/x86
The V7/x86 installer requires that a partition exists with the correct partition type. It ships with a tool called ptdisk to do that, but because /boot/mbr does not exist on the installation environment, it cannot initialize a disk that does not already have a partition table (http://www.nordier.com/v7x86/files/ISSUES). Thus I used a (recent) release of FreeBSD to create it. At first, FreeBSD couldn’t find its own CD-ROM, which left me quite confused. As it turns out, it being unable to find the CD-ROM was a side effect of assigning only 64 megabytes of RAM to the virtual machine. Once I’d bumped the RAM to 1GB, the FreeBSD booting procedure worked and I could create the partition for V7/x86. V7/x86 itself comes packaged on a standard ISO file and with a simple installation script. It seems it requires an IDE drive, but I did not investigate support for other types of hard drives, in particular SATA drives, much further. There seem to be no USB drivers, so USB keyboards may not work, either.
During the installation, my hard drive started making a lot of scary noises for a few minutes, so I aborted the installation procedure. After moving the disk image to a RAM disk (thank you, Linux, for giving me the power of tmpfs), I restarted the installation and it went in a flash. The scary noises were probably related to copying data with a block size of 20, which I assume was 20 bytes per block: The virtual hard disk was opened with O_DIRECT, i.e., all writes got flushed to it immediately. Rewriting the hard drive sector 20 bytes at a time must’ve been rather stressful for the drive.
4. Using V7/x86
I thought I knew my UNIX , but the 70s apparently had a few things to teach me. Fortunately, getting the system into a usable state was fairly simple because http://www.nordier.com/v7x86/doc/v7x86intro.pdf got me started. The most important notes are:
1.
V7 boots in single-user mode by default. Only when you exit single-user mode, /etc/rc is actually run and the system comes up in multi-user mode.
2.
Using su is recommended because root has an insane environment by default. To erase, # is used, rather than backspace (^H). The TERM variable is not set, breaking vi. /usr/ucb is not on the path, making more unavailable.
3.
The character to interrupt a running command is DEL, not ^C. It does not seem possible to remap this.
more is a necessity on a console. I do not have a teletype, meaning I cannot just ‘‘scroll’’ by reading the text on the sheet so far. Therefore, man is fairly useless without also piping its output to more.
Creating a user account was simple enough, though: Edit /etc/passwd, run passwd for the new user, make the home directory, done. However, my first attempt failed hard because I was not aware of the stty erase situation. I now have a directory in /usr that reads ‘‘xorhash’’, but is definitely not the ASCII string ‘‘xorhash’’. It’s ‘‘o^Hxorhash’’. The same problem applies to hitting the arrow keys out of habit to access the command history, only to butcher the partial command you were writing that way.
Another mild inconvenience is the lack of alternative keyboard layouts. There is only the standard US English keyboard layout. I’m not used to it and it took me a while to figure out where some relevant keys ($, ^, &, / and – in particular) are. Though I suppose if I really wanted to, I could mess around with the kernel and the console driver, which is probably the intended way to change the keyboard layout in the first place.
5. Writing a document
Equipped with a new user, I turned to writing this text down before my memory fails me on the installation details.
5.1. The vi Editor
I am infinitely thankful for having vi in the V7/x86 distribution. Truly, I cannot express enough gratitude after just seeing a glimpse of ed in the V7/x86 introduction document. It has some quirks compared to my daily vim setup, though. Backspacing across lines is not possible. c only shows you until where you’re deleting by marking the end with $. You only get one undo, and undoing the undo is its own undo entry. And of course, there’s no syntax highlighting in that day and age.
5.2. troff/nroff
And now for the guests of this show for which the whole exercise was undertaken. The information in volume 2A of the 7th Edition manuals was surprisingly useful to get me started with the ms macros. I didn’t bother reading the troff/nroff User’s Manual as I only wanted to use the program, not write a macro package myself. The ms macro set seemed to be the way to go for that. In this case, nroff did much more heavy lifting than troff. After all, troff is designed the Graphic Systems C/A/T phototypesetter. I don’t have one of those. M. E. Lesk’s Typing Documents on the UNIX System: Using the −ms Macros with Troff and Nroff and Brian W. Kernighan’s A TROFF Tutorial proved invaluable trying to get this text formatted in nroff.
The ‘‘testing’’ cycle is fairly painful, too. When reading the nroff output, some formatting information (italics, bold) is lost. more can only advance pagewise, which makes it difficult to observe paragraphs in their entirety. It also cannot jump or scroll very fast so that finding issues in the later pages becomes infuriating, which I solved by splitting the file up into multiple files, one for each section heading.
5.3. The refer program and V7/x86
Since I was writing this in roff anyway, I figured I might as well take advantage of its capabilities – I wanted to use refer. It is meant to keep a list of references (think BibTeX). Trying to run it, I got this:
$ /bin/refer
/bin/refer: syntax error at line 1: ‘)’
unexpected
The system was trying to run the file as shell script. This also happens for tbl. It was actually an executable for which support got removed during the port (see https://pastebin.com/cxRhR7u9). I contacted Robert Nordier about this; he suggested I remove the -i and -n flags and recompile refer. Now it runs, exhibiting strange behavior instead: https://pastebin.com/0dQtnxSV For all intents and purposes, refer is quite unusable like this. Fixing this is beyond my capacity, unfortunately, and (understandably) Robert Nordier does not feel up to diving into it, either. Thus, we’ll have to live without the luxury of a list of references.
6. Getting the Data off the Disk
I’m writing this text on V7/x86 in a virtual machine. There are multiple ways I could try to get it off the disk image, such as via a floppy image or something. However, that sounds like effort. I’ll try to search for it in the raw disk image instead and just copy it out from there. Update: I’ve had to go through the shared floppy route. The data in this file is split up on the underlying file system. Fortunately, /dev/ entries are just really fancy files. Therefore, I could just write with tar to the floppy directly without having to first create an actual file system. The host could then use that “floppy” as a tar file directly.
Even when I have these roff sources, I still need to get them in a readable format. I’ll have to cheat and use groff -Thtml to generate an HTML version to put on the blog. However, to preserve some semblance of authenticity, I’ll also put the raw roff source up, along with the result of running nroff over it on the version running on V7/x86. That version ofnroffattributes the trademark to Bell Laboratories. This is wrong. UNIX is a registered trademark of The Open Group.
7. Impressions
ChuckMcM was right. When you’re grateful for vi, staring at a blob of text with no syntax highlighting and with limited space, you start appreciating troff/nroff much more. In particular, LaTeX tends to have fairly verbose commands. Scanning through those without syntax highlighting becomes more difficult. However, ‘‘parsing’’ troff/nroff syntax is much easier on one’s mind. Additionally, the terse commands help because
\section{Impressions}
stands out much less than
.NH
Impressions
.PP
That can be helped by adding whitespace, but then you remove some precious context on your tiny 80×24 screen. troff/nroff are very much children of their time, but they’re not as bad as I may have made them look last time. Having said that, there’s no way you’ll ever convince me to actually touch troff/nroff macros.
As for the system as a whole, I was positively surprised how usable it was by today’s standards. The biggest challenge is getting the system up and shutting it down again, as well as moving data to and from it. I did miss having a search function whenever I was looking for information on roff in volume 2A of the manual.
I have the greatest of respect for the V7/x86 project. Porting an ancient operating system that hardcoded various aspects of the PDP-11 in scattered places must have been extremely frustrating. The drivers were written in the ancient version of C that is used on V7 (see /usr/sys/dev).
I’ve been on a trip on the memory lane lately, digging around old manuals of UNIX® operating system before BSD.†In doing so, I’ve come across the sources for the 7th Edition manuals. I wanted to show one part of volume 2A to other people, but didn’t want to make them download the entire 336 pages of volume 2A for the part in question. The part I wanted to extract was “LEARN — Computer-Aided Instruction on UNIXâ€, starting at p. 107 in the volume 2A PDF file).
A normal person would, I presume, try to split the PDF file. That is straightforward and produces the expected results. I believe I needn’t state that you wouldn’t be reading this if I solved this problem like any sane person would. Instead, I opted to rebuild the PDF from the troff sources provided at the link above.
So I knew what I needed to do: Get the troff sources. I asked that the Heavens have mercy on my poor soul if this requires a lot of adjustment for 2017 text processing tools. However, a man must do what a man must do. The file in question was called “vol2/learn.bunâ€. I had no idea what a bun file is, hoped it wasn’t related to steamed buns and clicked it. As it turns out, it’s just what we would call a self-extracting archive today. The shell commands are not very weird, so the extraction process actually worked out just fine. Now I had files “p0†through “p7â€. Except what happened to “p1â€, the world will never know.
First Steps
I’ve dabbled in man pages before, but that was mostly mandoc, not actual troff.
Accordingly, the first attempt at getting something going was as naive as it could get: $ groff -Tpdf p* | zathura -
It led to, shall we say, varying results.
really butchered rendering attempt
Clearly, I was doing something very fundamentally wrong. Conveniently, volume 2A also had a lot of troff documentation. Apparently I was supposed to pass -ms and first run tbl(1) over the troff source before actually giving it to groff. That sounded like a good idea, but the results were still somewhat off:
not very butchered rendering attempt
Allow me to express my doubts that this text was written in 2017. If you compare the output with the known-good PDF, you’ll also notice that, somehow, “Bell Laboratories, Murray Hill, New Jersey 07974†turned into “CAIâ€. Unfortunate.
Back to Square One and Pick Up the Breadcrumbs
Continuing to read the page I got the learn.bun from, I also spied a section called “Macros and Referencesâ€. That sounds relevant to my interests. tmac.s, which after studying groff(1) seems to be what would get used with -ms references some files in /usr/lib/tmac. I was not in the mood to let this flood over into my system, so I had to make minor adjustments and turn it into relative paths. I also renamed tmac.s to tmac.os to avoid colliding with the one provided by groff, making the new invocation:
Every time the .UX macro was requested, I got: warning: macro `ev1' not defined (possibly missing space after `ev')
environment stack underflow
Point 1 was easy to address, it’s a simple text change. Point 2 was caused by spurious dots in front of a call to .ND. However, the actual volume 2A PDF said a different date than in the file, so I adjusted that to match (June 18, 1976 to January 30, 1979).
And Down the Slippery Slope
As for points 3 and 4… Let’s just say groff/troff macros are definitely not meant to be written or read by humans and it’s a feat comparable to magic that someone wrote this set of troff macros. Line 806 is .ch FO \\n(YYu. Supposedly, that changes the location of a page trap when the given macro is invoked. The second argument is meant to be a distance, which explains why groff is complaining. I tried to checked what groff does and left none the wiser. FO seems related to the page footer, I seemed to get away with just deleting that line, though.
Finally, point 4. Apparently, .ev1 was used multiple times in the tmac.os. This looked like it should’ve been .ev 1 instead. Changing those, lo and behold, .UX stopped behaving funky for the most part. Yet for some reason, I’d still get multiple footnotes about the trademark ownership of the UNIX® trademark.† tmac.os sets a troff register (GA) when the .UX macro is first encountered so that the footnote is only made once. The footnote is being made twice. Something does not add up here..AI (author’s institution) resets GA, but the first .UX comes after.AI, so that’s not the problem. Removing the .AB/.AE macros from page 1 caused only one footnote to be made. Thus, I infer it’s actually intended behavior that the footnote is made once for the abstract and once for the main body. Checking with the volume 2A PDF again, I realized that point 4 was, in fact, fixed just by the ev1 changes and I was just chasing a bug that does not exist. I really should’ve checked the PDF twice.
The abstract finally looks okay.
good rendering attempt
Done! Wait, No, Almost
Okay, we’re done, we can go home, right? Almost, one last thing to do: On the last page, there’s something really important missing: the bibliography. Instead, there’s just “$LIST$†there. We can’t just turn Brian W. Kernighan and Michael E. Lesk into plagiarists!
Back to the troff documentation in volume 2A, there’s a match for “$LIST$†on p. 183. Apparently I need a reference file and preprocess the file with refer(1). That sounds simple enough. Fortunately, I got the reference file along with the macros above, so I didn’t have to look for that separately.
Of course. Why would it work? That’d have been too much to ask for.
At least I get some nice hints:
refer:p2:148: no matches for `skinner teaching 1961'
refer:p3:114: no matches for `kernighan editor tutorial 1974'
The troff documentation conveniently explains the format for the reference file, so I could just add these two entries to Rv7man and be done with it. Thankfully, the pre-compiled PDF of the volume 2A manual had the information necessary to compile the bibliography entries with.
%T Why We Need Teaching Machines
%A B. F. Skinner
%J Harvard Educational Review
%V 31
%P 377-398
%D 1961
%T A Tutorial Introduction to the Unix Editor ed
%A B. W. Kernighan
%D 1974
The Heavens were feeling somewhat merciful, but only just enough that I could waste no more than a day on this project. They really wanted me to spend that day on it, though.
I will never, ever touch troff/groff again. mandoc is good at what it does and I’ll stick to mandoc for writing man pages. But if I ever need to get something typeset nicely from plain text?
LaTeX is the answer.
Not troff.
Never troff.
Not even once.
†UNIX® is a registered trademark of The Open Group.
I’m xorhash, a guest poster, here to talk about my tale going down a trip on the memory lane with QuakeNet’s service bot Q. If you’re not interested in IRC, you can probably skip this one.
On the Trails of Q
As far as I know, QuakeNet’s service bot Q went through these three major codebases:
There’s a reason I didn’t have anything to link for (a). That’s because to the best of my knowledge and research, no version has survived these past decades.
As for (b), it seems only the linked version 3.99 from the year 2003 was saved.
The CVS repository and thus commit history has been lost.
If anyone has either actual code for the old Perl Q or the CVS repo for the old
Q written in C, please reach out to me via `xorhash ++at++ protonmail.com’.
I’m most interested in looking through it.
However, not all hope was lost with the old Perl Q. As it turns out, most likely, the old Perl Q was actually based on an off-the-shelf product called “CServe”. What makes me think so?
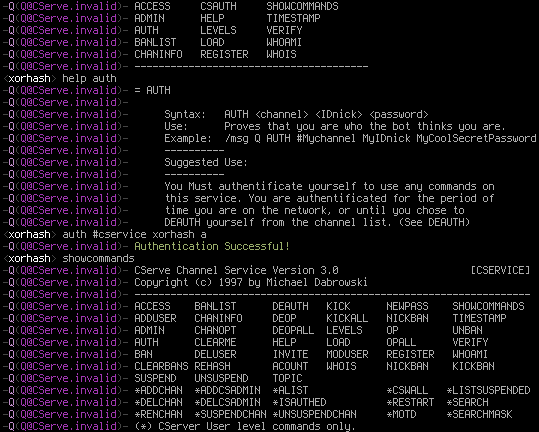
Let’s take a look at [the QuakeNet Q command listing from 1998.
I picked the command “WHOIS” and googled its use “Will calculate a nick!user@host mask for you from the whois information of this nick.” This lead me to a help file for StarLink IRC. At the top, it reads:
CStar3.x User Command Help File **** 09/10/99
Information extracted from CServe Channel Service
Version 2.0 and up Copyright (c)1997 by Michael Dabrowski
Help Text (c)1997 (c)1997 StarLink-IRC (with permission)
Wait a second, “CServe Channel Service”? I know that from somewhere.
So the commands between that help file and the QuakeNet Q command listing match up and so does Q’s host today. Most likely, I’m on the right track with this. What’s left is to track down a copy of CServe.
Note: I’ve been on the old Perl Q for a while and this strategy didn’t use to work. It seems Google newly indexed these pages. For once I can sincerely say: Thank you, Google.
The only surviving versions are 3.0 and 5.1. CServe got renamed to “CS” starting with 5.0 and was rewritten in C by someone other than the original CServe author, going by the comments in the file header of CS5.1 `src/show_access.c’. CS was actually sold as a commercial product. I wonder how many people bought it.
QuakeNet most likely took a version between 2.0 and 4.0, inclusive, as the basis for the old Perl Q. Which one in particular it was, we may never know. If you have any details, please reach out to me at the e-mail address above.
I can’t make any clever guesses anyway since the only versions that the web archive has are 3.0 and 5.1. The latter is written in C, so it quite obviously can’t be the old Perl Q.
Making It Run
So now that I have CServe 3.0, I wanted to actually see it running.
There are three ways to reasonably accomplish this:
a. port CServe to a modern IRCd’s server-to-server protocol,
b. port an old IRCd to a modern platform,
c. emulate an old platform and run both IRCd and CServe there.
I chose option (b).
Once upon a time, I did option (a) for the old UnderNet X bot. It was a very painful exercise to port a bot that predates the concept of UIDs (or numeric nicks/numnicks as ircu’s P10 server-to-server protocol calls them). There’s nothing too exciting about doing (c) by just emulating a 486 or so and FreeBSD, just sounds like a boring roundtrip of emulation and network bridging.
Fortunately, the author was a nice person and wrote on the CServe website that version 3.0 requires “ircu2.9.32 and above”.
It seems the ircu2.10 series followed right after ircu2.9.32. While I’m sure there’s some linking backwards compatibility, determining which ircu in the ircu2.10 series still spoke enough P09 to link with CServe sounded like an exercise in boring excruciating pain. Modern-day ircu most certainly no longer speaks P09. Besides, what’s the fun in just doing the manual equivalent of `git bisect’?
So after grabbing ircu2.9.32, I tried to just straightforward compile and run it.
There’s a `Config’ script that’s supposed to be kind of like autoconf `configure’, but I’ve found it extremely non-deterministic. It generates `include/setup.h’. I’ve made a diff for your convenience. It targets Debian stable, and should work with any reasonably modern Linux. There are special `#ifdef’ branches for FreeBSD/NetBSD in the code. This patchset may break for BSDs in general.
Do not touch `Config’, meddle with `include/setup.h’ manually. Remember this is an ancient IRCd, there are actual tunables in `include/config.h’.
The included example configuration file is correct for the most part, but the documentation on U:lines is wrong. U:lines do what modern-day U:lines do, i.e., designate services servers with uber privileges.
U:cserve.mynetwork.example:*:*
Excuse Me, But What The Fuck?
Of course, I’m dealing with old code. It wouldn’t be old code if I didn’t have some things that just make me go “Excuse me, but what the fuck?”
Looping at the speed of light
aClient *find_match_server(mask)
char *mask;
{
aClient *acptr;
if (BadPtr(mask))
return NULL;
for (acptr = client, (void)collapse(mask); acptr; acptr = acptr->next)
{
if (!IsServer(acptr) && !IsMe(acptr))
continue;
if (!match(mask, acptr->name))
break; continue;
}
return acptr;
}
See that `continue’ way on the left? What is it doing there? Telling the compiler to loop faster?
Carol of the Old Varargs
So apparently some of this code predates C89. Which means it uses old-style declarations, but that’s okay. It also uses old-style varargs, which is adorable.
The hacks around not even that being there are adorable, too:
These functions were declared like this (the example chosen above actually has
no declaration because why not):
/*VARARGS1*/
extern void sendto_ops();
Whatcmp
There are `mycmp’ and `myncmp’ for doing RFC1459 casemapping string comparisons. `strcasecmp’ got `#define’d to `mycmp’, but in one case `mycmp’ got `#define’d back to `strcasecmp’. It seemed easier to just remove `mycmp’, replacing it with `strcasecmp’ and forgo RFC1459 casemapping. This is doubly useful because CServe doesn’t actually honor RFC1459 casemapping.
Waiting for the Cookie
ircu uses PING cookies. I was rather confused when I didn’t get one immediately after sending `NICK’ and `USER’. In fact, it took so long that I thought the IRCd got stuck in a deadloop somewhere. That would’ve been a disaster since the last thing I wanted to do is get up close and personal with the networking stack.
As it turns out, it can’t send the cookie:
/*
* Nasty. Cant allow any other reads from client fd while we're
* waiting on the authfd to return a full valid string. Use the
* client's input buffer to buffer the authd reply.
* Oh. this is needed because an authd reply may come back in more
* than 1 read! -avalon
*/
Nasty indeed.
I lowered `CONNECTTIMEOUT’ to 10 in the diff linked above. This makes the wait noticeably shorter when you aren’t running an identd.
CServe Isn’t Much Better
Not that CServe is much better. I have to hand it to Perl, I only needed to undo the triple-`undef’ on line 450 of `cserve.pl’ and it worked with no modifications. God bless the backwards compatibility of Perl 5.
That said, it has its own interesting ideas of code. This is the main command execution:
Yep, it opens, reads into an array, closes and then evals. For every command it recognizes. Of course, this means code hot swapping, but it also means terrible performance with any non-trivial amount of users.
Oh, and all passwords are hashed. But they’re hashed with `crypt()’. And a never-changing salt of ZZ.
End Result
up & running
Was it worth it?
No, not really.
Would I do it again? Absolutely.
You probably do not want to expose this to the outside world.
The IRCd code is scary in all the wrong ways.
Further Links
Some other things if you’re into ancient IRC stuff:
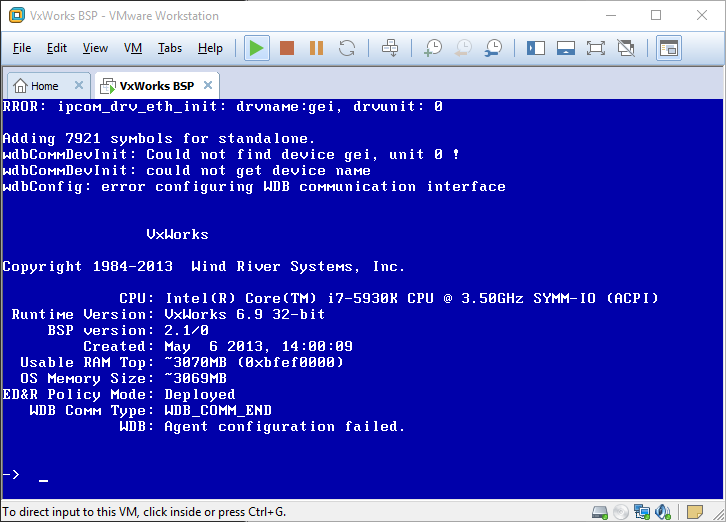
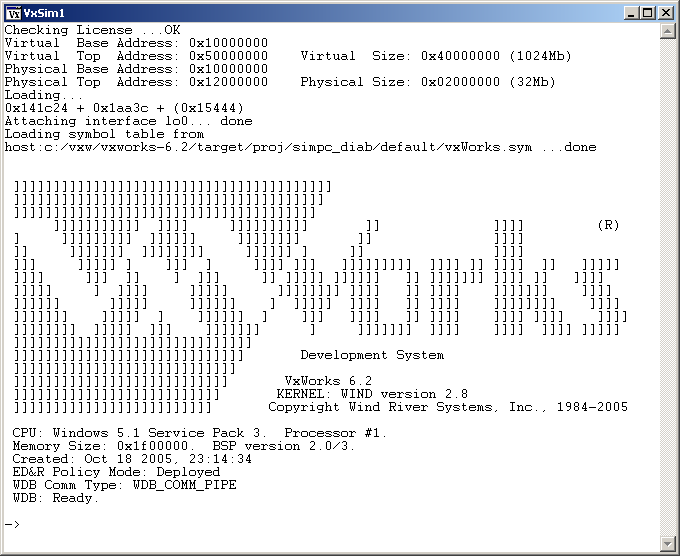
VxWorks is an embedded operating system that typically runs on things like Mars probes, Boeing 787 or Apache helicopters, but today you can run it too! WindRiver has an evaluation target that you can run on an Intel CPU, meaning you can spin it up on your favorite hypervisor at home.
VxWorks comes with two shell modes C and admin. In C shell you execute C code and you can write simple programs or even patch existing running code like they did on Mars Pathfinder. This is the default one with -> prompt. You can enter to admin shell by typing “cmd”. If you are familiar with KSH “vi” mode you can use it for history and editing command line.
The evaluation target is very basic and limited. If you want to do and learn more stuff, you need to download evaluation of VxWorks Platform and spin up the VxWorks Simulator, or build your own target. This is a picture of a slightly older version running on Windows:
The operating system was also recently featured in Forbes…