
You probably don’t want to do this. Unless you enjoy giant empty islands. Maybe you just want to play it on an inaccessible network. Maybe your social anxiety is so bad that you like the idea of playing a MMO alone. It’s probably not a good idea to do this, in that at the end you’ll get bored quickly, but here we go!
Using Ubuntu 16.04 the steps on github.com/TheAnswer/Core3 got me running quick enough. It is rather intense to built, and for the most part it’s pretty easy, although running documentation seems to be … elsewhere. I’m sure it is somewhere, but I have no idea where.
The big thing to do is update the galaxy binding in the mysql database to reflect either the LAN address for local play, or the WAN address if you are natting/hosting on the internet.
mysql -uswgemu -p123456 swgemu -e “update galaxy set address=’192.168.13.128′ where galaxy_id=2;”
And for the heck of it, I thought I’d build swgemu for both 16 (swgemu-binary-Ubuntu_16.04.6_LTS_x86_64.tar.gz) & 18 (swgemu-binary-Ubuntu_18.04.2_LTS_x86_64.tar.gz). Keeping in mind for 18, that mysql was dumped for mariadb, so you need different packages. For a fresh 16 server, it’d go something like this:
apt-get install openssh-server
mkdir /tre
chown swgemu:swgemu /tre
(from a client machine)
pscp *tre [email protected]:/tre
apt-get install mysql-server screen libatomic1 libmysqlclient20 liblua5.3-0
tar -zxf swgemu-binary-Ubuntu_16.04.6_LTS_x86_64.tar.gz
cd swgemu
./sqlstuff.sh
mysql -uswgemu -p123456 swgemu -e "update galaxy set address='192.168.13.128' where galaxy_id=2;"For version Ubuntu 18, you want the package mariadb-server & libmariadbclient18 instead of the mysql versions.
Make sure to set the TrePath!!!
vi conf/config.lua
Run the server, either under screen (./run.sh) or directly ./core3 if everything is going well, the [Core] will come up initialized..
(27 s) [AuctionManager] bazaar Checked 0 auction item(s) and updated 0 item(s)
(27 s) [AuctionManager] Bazaar terminal checks completed in 0ms
(27 s) [AuctionManager] Checking 0 vendor terminals
(27 s) [AuctionManager] vendor Checked 0 auction item(s) and updated 0 item(s)
(27 s) [AuctionManager] Vendor terminal checks completed in 0ms
(27 s) [AuctionManager] loaded auctionsMap of size: 0
(27 s) [FrsManager] ERROR - Unable to initialize frs manager, yavin4 disabled.
(27 s) [StatusServer] initialized
(27 s) [Core] initialized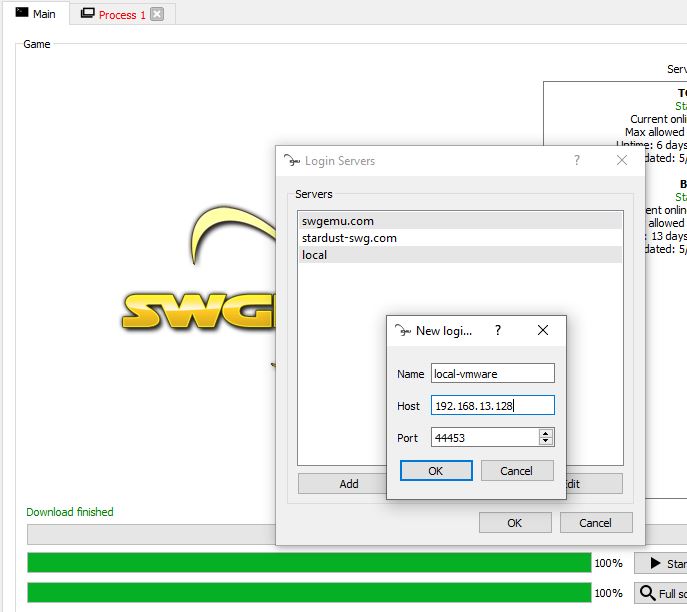
After that, you can add the new server as a login server from the swgemu launcher, and start it up. By default it will allow anyone to create a user with any password.
And here we are, all alone.


{kind=link}