(this is a guest post from Tenox)
Archive.org is now hosting 900+ arcade games that run under JavaScript port of MESS.
Game on!

(this is a guest post from Tenox)
Archive.org is now hosting 900+ arcade games that run under JavaScript port of MESS.
Game on!
Fortran users of the world, rejoice!
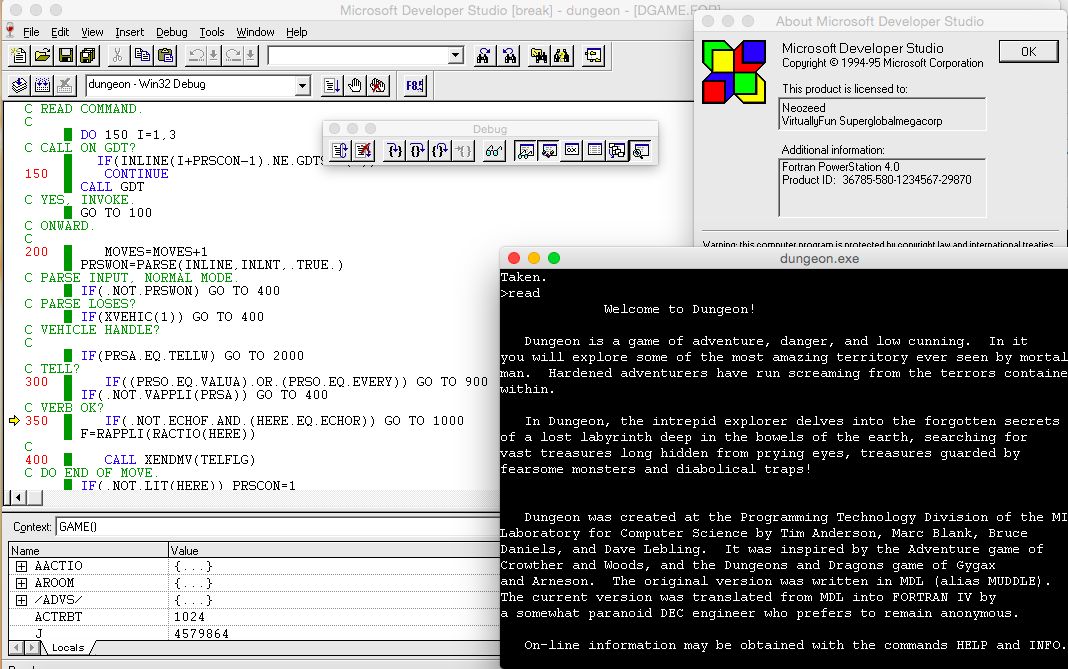
Dungeon being debugged
Not only does the CLI tools run, and compile stuff like say Dungeon, but much to my surprise, the UI works, and even better so does the debugger!
Personally, I’ve always preferred the Microsoft debugging tools.
Very cool, if I do say so myself.
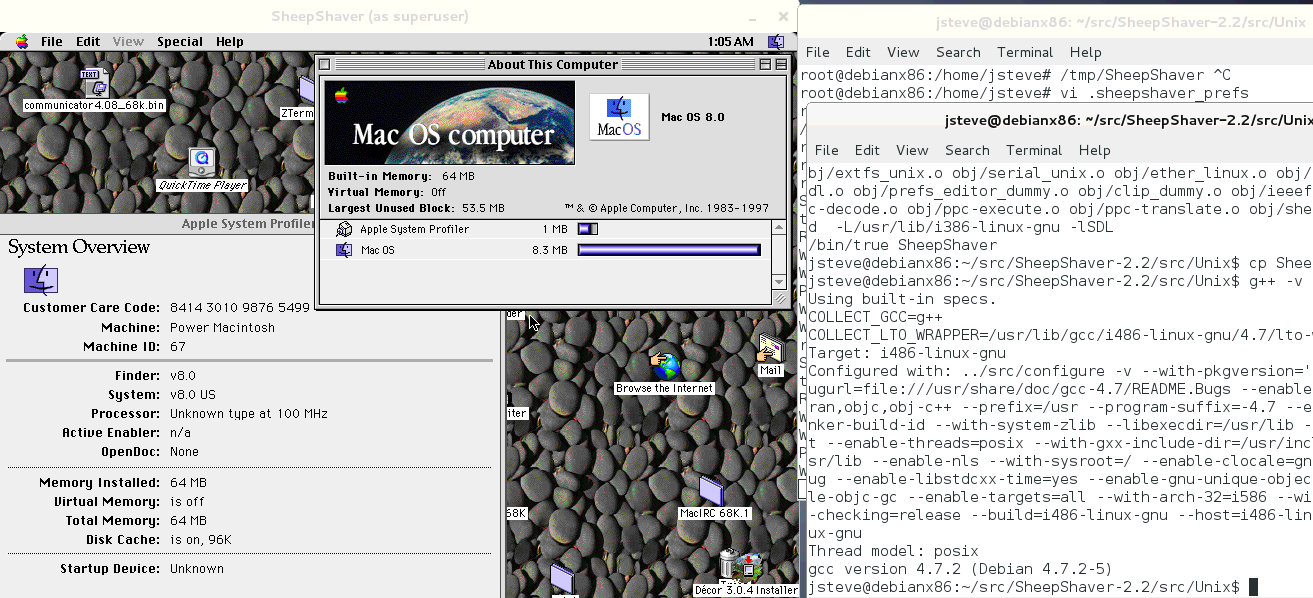
SheepShaver on Linux
Only because people were asking for it. Â The first thing I did for Basilisk II was to get it building on Linux, so here we are. Â I only tweaked the config process to let me build it with GCC 4.7.2 .
So this will be in the same effort of removing features, and trying to place in my SDL drivers, network and SCSI stuff.
Im starting with SheepShaver v2.2, which is pretty old. Â But 700kb compressed is a good starting point. Â As you can see it boots MacOS 8.0 which is also good enough for me.
The other questions will be, can this build under Windows with MinGW configured like this, and can it build with OS X. Â It looks like all the stuff is there so this may be kind of easy. I hope.
Also SheepShaver does something funky with it’s memory space, it does some direct mapping to the user area. Â I’ll have to see if I can disable that, performance be damned (well I turned off JIT as it won’t compile with 4.7 either) so this won’t be fast, but I’m just patching stuff up, not re-implementing the wheel here.

Probably not a good idea..
I never got into the whole ‘desktop search’ thing as I used to know where my stuff was. But now we live in the future where not only can you just go out and buy terabytes worth of storage but downloading 10 years’ worth of usenet is something you can accomplish in a few minutes (on a good connection) but storing it as flat files only takes 20 minutes to decompress some 2,070,332 worth of files is a trivial manner. It’s really cool to live in the future.
Total Files Listed: 2070332 File(s) 5,429,376,673 bytes
168164 Dir(s) 1,119,884,468,224 bytes free
Now what about finding something in those files?
I should be embarrassed as I was using grep.
Yes, in my hunt for obscure information grep was my tool of choice.
So, after Frank had mentioned it in passing, if I’d ever used AltaVista Personal Search 97 before I thought I’d give it a bit of a test. First, I unpacked some BSD source code, and had it index that. The results were incredibly FAST. So the next thing to do was to try the UTZOO archives. I should have expanded my NT 4.0 VM’s disk first, but I got this far until I was down to 200MB of free disk space
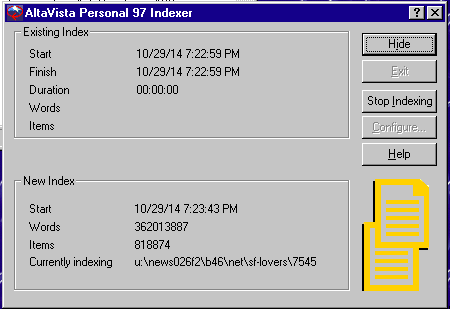
I should add that I’m sharing the UTZOO archvie over the network. Not the fastest way at all. And I only made it about 40% the way through the archive. Even at this point the search database is only 1.2GB
So how does it run? Well, it’s a localized web service that resides on your desktop. Of course, it only works when you request from 127.0.0.1 as they sold a network searchable version of AltaVista, the Workgroup Edition. Even this was a retail product at one point retailing for $29 to $35
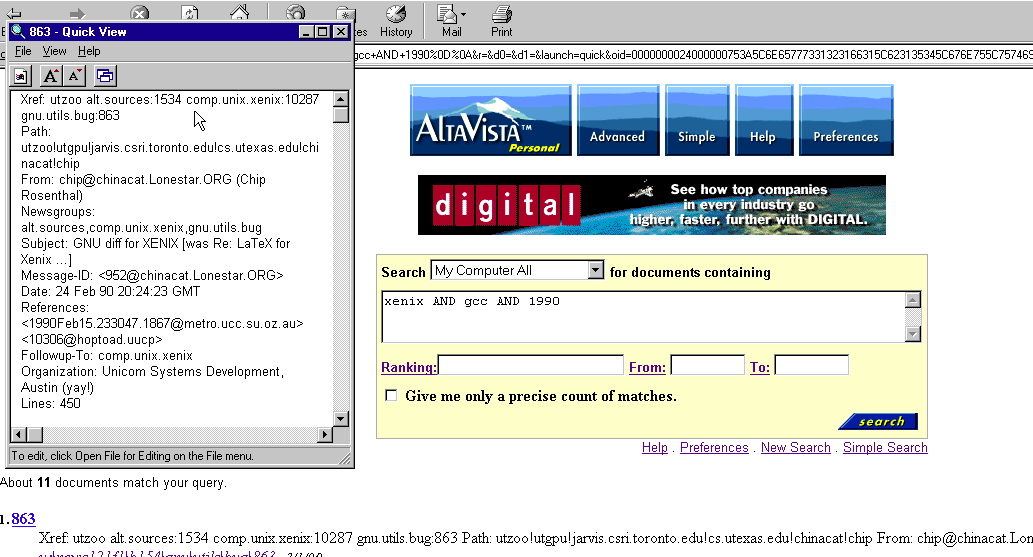
Show me the Xenix!
So, you hit the web page, type in your search, and you get an answer like immediately. It really is scary how fast this thing is. Although the results can need a lot of tweaking, but we are talking 800,000 files.
But needless to say, there was the disastrous Compaq buyout of DEC, and the entrance of Google, and it was over. From what I understand people are still selling the workgroup/enterprise search. I can see why even though the 97 is rough it still has promise.

What a bargain!
For anyone who cares, it’s geared to Windows 95, or Windows NT 4.0.. 2000 and beyond is at your own risk. It uses a Win16 setup program, so Windows 7 x64 was out of the question, but you can download it here.
Well, I thought it was funny.
I came across this PDP-11 version. Â I saved it to the side while I was looking for my main target.
Now I’ve tried to compile it on contemporary UNIX of the time, namely Unix v7, 2.9 BSD and 2.10 BSD and they fail at the same point:
hack.monst.c:99: Too many initializers: mon
*** Error code 1
Stop.
What is more weird is I didn’t see anyone having any reports of it working, just requests for the code. Â Although I have been able to compile and run it on 4.2BSD/VAX. Â So it must be a cc/pcc thing, or some other C compiler they are using on the PDP-11 in Amsterdam circa 1985. Â And then I found this interesting bit:
Date-Received: Mon, 22-Apr-85 06:57:56 EST
References: <[email protected]>
Reply-To: [email protected] (Andries Brouwer)
Distribution: net
Organization: CWI, Amsterdam
Lines: 11
In article <[email protected]> [email protected] (Chuck McManis) writes:
>… about the PDP-11 version of hack …
>All in all it doesn’t seem to do 90% of the things that make it different
>from rogue.
The PDP-11 version of hack is a slightly improved (by people at the VU,
Amsterdam) version of some code that was stolen from my directory
some three years ago; it was being worked on, and certainly not in a
shape fit for distribution. Thus, as you noted, it doesnt have half
of the features present in hack, and, what is worse, it is very buggy.
I am sorry it was distributed.
Which to me is kind of interesting as this recently happened on September 21st:
The NetHack Development Team feels it is necessary to publicly address an issue that has surfaced in the last week.
Recently a NetHack source distribution has appeared, claiming to be NetHack 3.5 or 3.5.0 or 3.4.4.
This claim is partially correct. This is our code. However it was not released by us or with our authorization. This code is not ready for release: it is unfinished, unpolished, and almost certainly very buggy. It has not been play-tested for balance or functionality. It is best considered a partial and unfinished rough draft. We will not be supporting this code, nor will we be releasing binaries or bugfixes for it. It will not be available through our website.
Due to this incident and to prevent confusion, we will not now nor in the future release anything with a version number of 3.4.4, 3.5, or 3.5.0.
We thank those of you who play and develop both NetHack and its many variants for your support and encouragement at this time and over the many years NetHack and its progeny have and continue to evolve.
So yeah it seems there is a long history of hacking hack, why even the Fortran port of Zork was born that way:
Zork (was) only as encrypted files that were runnable in an MDL environment but were not readable (and modifiable) as source code. They even went so far as to patch their famously insecure ITS development system, adding security to just the directory that stored the source. Hackers, however, won’t be denied, and soon one from DEC itself had penetrated the veil. From Infocom’s own official “History of Zork“:
[The security] was finally beaten by a system hacker from Digital: using some archaic ITS documentation (there’s never been any other kind), he was able to figure out how to modify the running operating system. Being clever, he was also able to figure out how our patch to protect the source directory worked. Then it was just a matter of decrypting the sources, but that was soon reduced to figuring out the key we’d used. Ted had no trouble getting machine time; he just found a new TOPS-20 machine that was undergoing final testing, and started a program that tried every key until it got something that looked like text. After less than a day of crunching, he had a readable copy of the source. We had to concede that anyone who’d go to that much trouble deserved it. This led to some other things later on.
Indeed,hackers won’t be denied.
The source code to Hack was posted onto usenet back in December of 1984:
From: [email protected] (funhouse) Newsgroups: net.games,net.sources Subject: Hack sources posted Message-ID: <[email protected]> Date: Mon, 17-Dec-84 09:11:48 EST Article-I.D.: mcvax.6238 Posted: Mon Dec 17 09:11:48 1984 Date-Received: Tue, 18-Dec-84 07:04:44 EST Organization: CWI, Amsterdam Lines: 20 Xref: watmath net.games:1303 net.sources:2185 I will post the sources for Hack to net.sources. They come in 10 parts; the total source is slightly over 400kbyte. Hack is a game resembling rogue (but much richer than the versions of rogue I have had access to). The game runs on all machines with sufficient address space: $ ls -l /usr/games/HACK -rws--x--x 1 play 159744 Nov 10 19:09 /usr/games/HACK $ size /usr/games/HACK text data bss dec hex 106496 34816 29264 170576 29a50 but if you are unfortunate enough to have a backward C compiler (without structure assignments or bitfields or functions returning structures or with only 6 significant chars to an identifier) then you'll have to work to get this running. I am happy with mail, but will be abroad the next four weeks. Good Luck & Happy Hacking !
Oddly enough the full source code to Hack had been lost.  Even the Nethack Wiki didn’t have the full source code, although thanks to the UTZOO archives by Henry Spencer, I was able to look through enough of the tapes since I had the date and subject in hand, and I was able to pull out the entire thing.
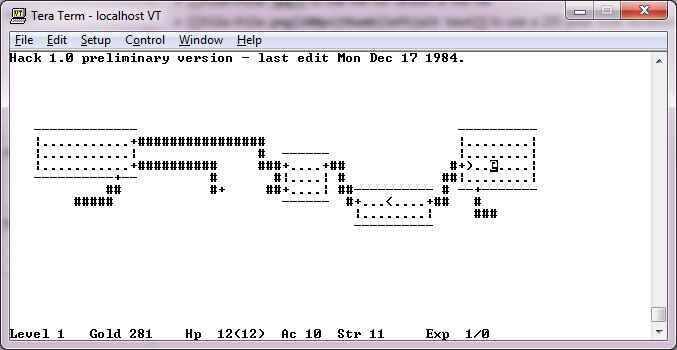
hack 1.0 preliminary version
I’ve added a package tape for SIMH, as it builds and runs on 4.2 BSD out of the box.
It’s really cool to have saved this from the digital dumpster, although it was there all along. Â And thanks to others for at least pointing out that part of it was missing or I’d never even look.
I’ve never been musically inclined, but for those who loved the whole tracker scene of 20 years ago, Jeffrey Lim has released the source code to Impulse Tracker!  It features an impressive sound card support list:
It’s all in assembly and can be built with Turbo Assembler 4.1
You can find the source code on bitbucket here. Github mirror!
I read somewhere that kids these days are interested in games where you can modify how the game operates with sub programs written in their own languages etc.

Hello
So while this does sound interesting, it does remind me of that good old fashioned syscall emulation, where you emulate the CPU, load an executable, but any system calls that are made, are handled by the simulator, little if any hardware is actually emulated. Yes Basilisk II is an example of this, but so is Wine, WOW, NTVDM, i386 code on x64 platforms, and various others. The major advantage is that they typically can access your native file system so you don’t have to mess with virtual disks. Of course it all depends on the implementation.
I did remember this old simulator, Apout, which could run UNIX v6, 7 along with BSD 2.9 stuff on modern Unix. The emulation layer here being LIBC, and how pretty much the basics of how UNIX operates hasn’t changed since those ancient days in the 1970’s.
So I thought I’d try to see how much of this works on Win32 using Microsoft Visual C++ 5. And surprisingly I didn’t have to glue in that much, the biggest thing I had to do was trying to detect if a file about to be opened was ASCII or BINARY as the UNIX platform doesn’t distinguish these two but Win32 with it’s MS-DOS legacy does. As you can see I did get the banner program running, some of the games work ok, although I had to comment out the sgtty functions as there is no immediate equivalent on Windows, and I didn’t think there would be that much of a demand for such a thing anyways. I can even run the login program. Which brings me to the issue which is that it’ll spawn new programs fine, but when an exit is called Apout just exits. Even on Linux it’ll just do this. I tried doing something with setjmp/longjmp but it crashes shortly afterwards… No doubt some stack unwinding fun. As such trying to compile things just bomb out. I went ahead and took the source code to cc and made a native Win32 version that then calls apout for the various parts and that almost worked except I then found out that the assembler on the PDP-11 is a 2 pass assembler, written in assembly. And yes, when as calls as2, and unwinds all hell breaks loose. Which is another problem that UNIX likes to share file descriptors among itself and children, but children like to close things when they die. I guess the solution is to give each child it’s own descriptor table as everyone likes to close stdin/stdout/stderr and even #4, which the simulator uses for logging. it’s very annoying so I just prevented it from closing handles under 4.
But running each of the phases manually does get me an executable but it doesn’t seem to do anything, the only syscalls are closing all the file handles and exiting.
So close!
I don’t think anyone will care, but here is my source/binary along with Unix v7. It’s hard coded to dump stuff into c:\temp for temporary files, the Unix v7 must be in c:\v7 … ugh.

Hunt the wumpus on NT
But yeah, you can play that thrilling game from 1979, hunt the wumpus!
So you know the drill, someone wants to do something with Solaris, and they’ve already installed the OS, and done a bunch of customization and whatnot, now they call up all in a panic as they copy in a binary distribution of GCC, but they can’t compile anything because they are missing values-Xa.o , or worse just about everything from the development tools.
Well I’m not sure about ancient Qemu, but 2.2 can mount the CD-ROM’s post install! … manually.
The poor guy didn’t want to re-install, but one option was to boot up the CD in single user mode, mount his disk, and copy the /cdrom path onto some partition so he could then install the packages as needed, and even better have the whole tree ready if need be.
But the better thing is to just mount the CD, install the package and be done with it right?
I’ve only tested this with Solaris 2.6…
While booting up single user mode from the CD (boot disk2:d -s) I noticed this line in the mount table:
/cdrom       (/devices/iommu@f,e0000000/sbus@f,e0001000/espdma@f,400000/esp@f,800000/sd@2,0:a):    0 blocks     0 files
So I thought I’d try to mount that once the copy was done. Â The first thing I did was make a symbolic link as that name is a little hard to type, and I didn’t want to remember that path after this day.
mkdir /cdrom
cd /dev
ln -s /devices/iommu@f,e0000000/sbus@f,e0001000/espdma@f,400000/esp@f,800000/sd@2,0:a jr0
this gives me a /dev/jr0 linking to where the Solaris 2.6 install path was.
# mount -oro /dev/jr0 /mnt
mount: /dev/jr0 is not this fstype.
Well that was disappointing. Â Could I even read the CD?
# head -1 /dev/jr0
CD-ROM Disc for SunOS Solaris Installation
Ok, so it must be the file-system type. Â The ‘bootable’ partition on the CD contains a SYSV filesystem, as it’s a “live CD”..
mount -o ro /dev/dsk/c0t2d0s1 /mnt
# ls /mnt
a dev kernel opt reconfigure usr
bin devices lib platform sbin var
cdrom etc mnt proc tmp
You can even fsck it!
# fsck /dev/dsk/c0t2d0s1
** /dev/dsk/c0t2d0s1 (NO WRITE)
** Last Mounted on /tmp/MntDev.12554
** Phase 1 – Check Blocks and Sizes
** Phase 2 – Check Pathnames
** Phase 3 – Check Connectivity
** Phase 4 – Check Reference Counts
** Phase 5 – Check Cyl groups
2445 files, 19114 used, 4873 free (17 frags, 1214 blocks, 0.0% fragmentation)
#
But the part of the CD-ROM that we want, with all the packages uses a different file-system, and with a bit of hunting I found the right string:
mount -F hsfs -r /dev/jr0 /cdrom
Now we can manually add in the missing packages!
# mount -F hsfs -r /dev/jr0 /cdrom
# ls /cdrom
Copyright Solaris_2.6
We just have to point the pkgadd command to where the CD-ROM is mounted. Â In my case I just had to type in:
pkgadd -d /cdrom/Solaris_2.6/Product/
And then I got the “interactive” mode showing off all 471 packages. Â Don’t just slam the enter key or you’ll start installing everything. Â Hit control-d and then we can manually add them in.
<RETURN> for more choices, <CTRL-D> to stop display:^D
Select package(s) you wish to process (or ‘all’ to process
all packages). (default: all) [?,??,q]:
And in this case, the packages I wanted were:
SUNWarc
SUNWbtool
With those installed, now I can see the object files I wanted:
# find / -name ‘*.o’ -print
/usr/lib/adb/adbsub.o
/usr/ccs/lib/values-Xa.o
/usr/ccs/lib/values-Xc.o
/usr/ccs/lib/values-Xs.o
/usr/ccs/lib/values-Xt.o
/usr/ccs/lib/values-xpg4.o
Wasn’t that great? Â Nobody had to re-install, no disk space is wasted, and now if other packages are needed, it’ll be easy to add them.