
(this is a guest post by Antoni Sawicki aka Tenox)
TL;DR
WRP now allows rendering web pages in to a simplified HTML, compatible with old browsers (in addition to Image Map).
Long version
WRP or “Web Rendering Proxy” is a proxy server that allows to use vintage web browsers on the modern web. Originally inspired by Opera Mini/Turbo rendering proxy for mobile devices. I wanted a similar service that would translate modern web pages, but in to it’s older HTML version. This not only proved very difficult, but I realized that the web is advancing in a way that it would not be very future proof. I’m talking about dynamic pages, JavaScript generated content and WASM. Instead, I took a different approach – generating a screenshot of a page with clickable Image Map. This allows to faithfully represent a fully rendered web page on a vintage machine + allow to click anywhere on it and perform actions. At a cost of performance. Rendering GIF or JPEG and transferring over network feels rather slow and clunky.
I have been using WRP for some 10 years now. I began to realize that, this approach, while pretty awesome for show and bragging, is not very practical for day to day use. In fact, my use of web browsers on vintage workstations typically revolves around reading documentation, blogs, wikis and other, “mostly text” websites. It would be much better if these were not clunky screenshots but rather some form of text output.
I again started poking around the original idea of simplified HTML. Looked at various reader modes, print to PDF, etc. In particular, I have noticed recent advancements in so called “web scraping”, extraction and html to markdown conversion services. Likely fueled by the recent AI/LLM craze, as robots scrape the web to learn about humans. What caught my attention are various “html to markdown” services. They can fully render dynamic JS pages and extract contents as it was in a browser. Also, Markdown, if you think about it, is in fact a simplified HTML.
After doing some research, in couple of evenings and less that 100 lines of code I got a basic version going. The principle is as follows: First capture the page HTML, convert to Markdown, do some manipulation like adding link prefixes and remove images (we’ll come back to that later). Then render Markdown back to HTML. Wrap it in a vintage HTML header an off we go. The results are amazing!!
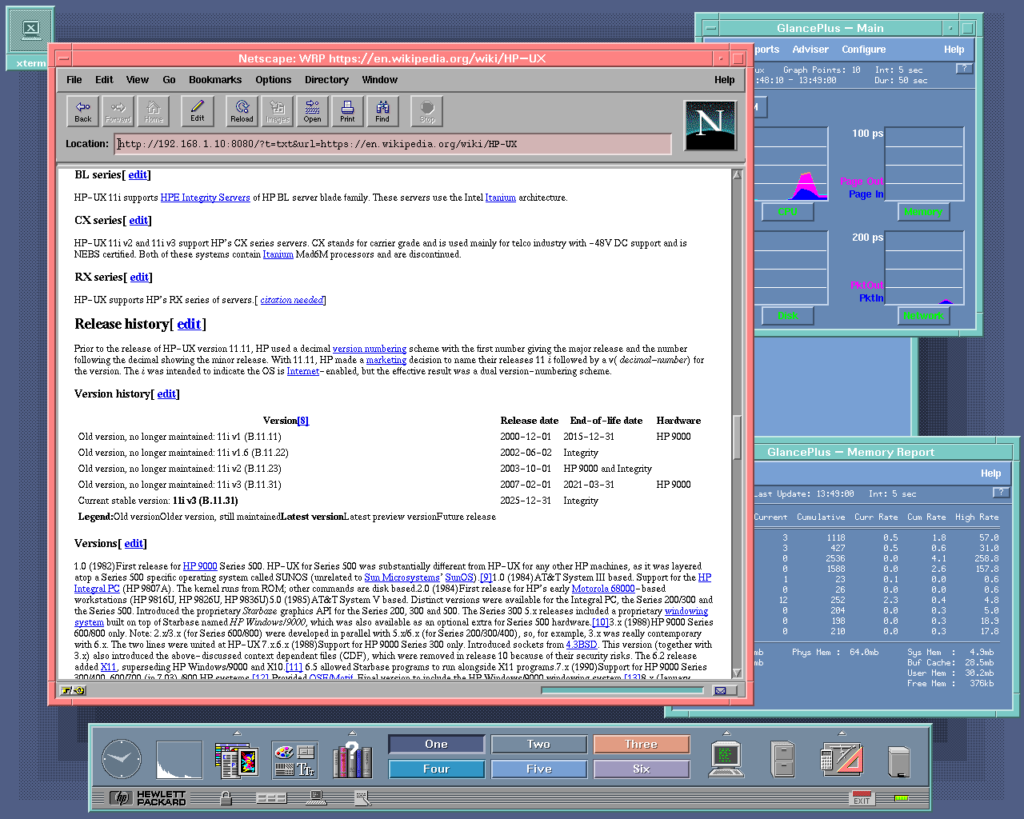
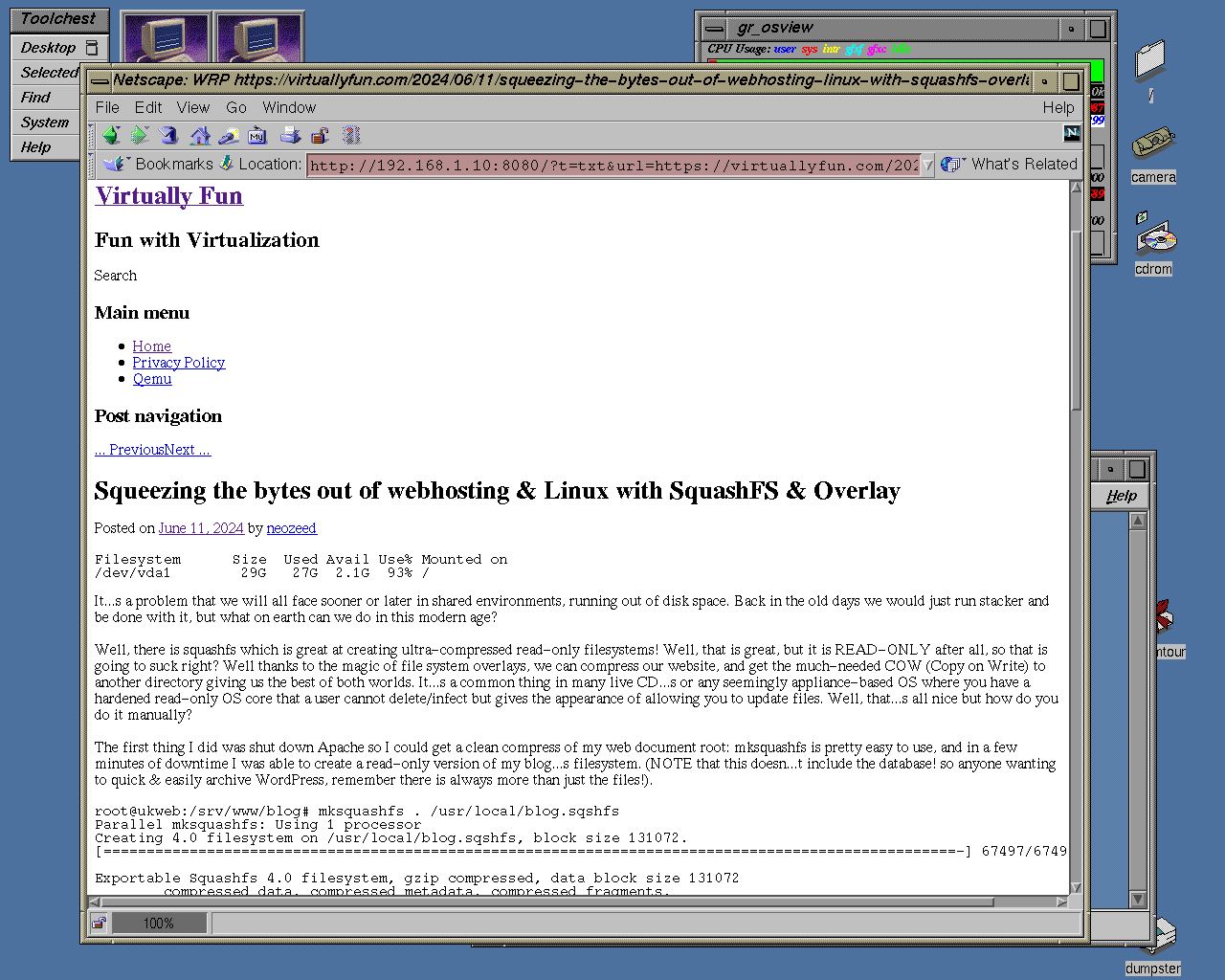
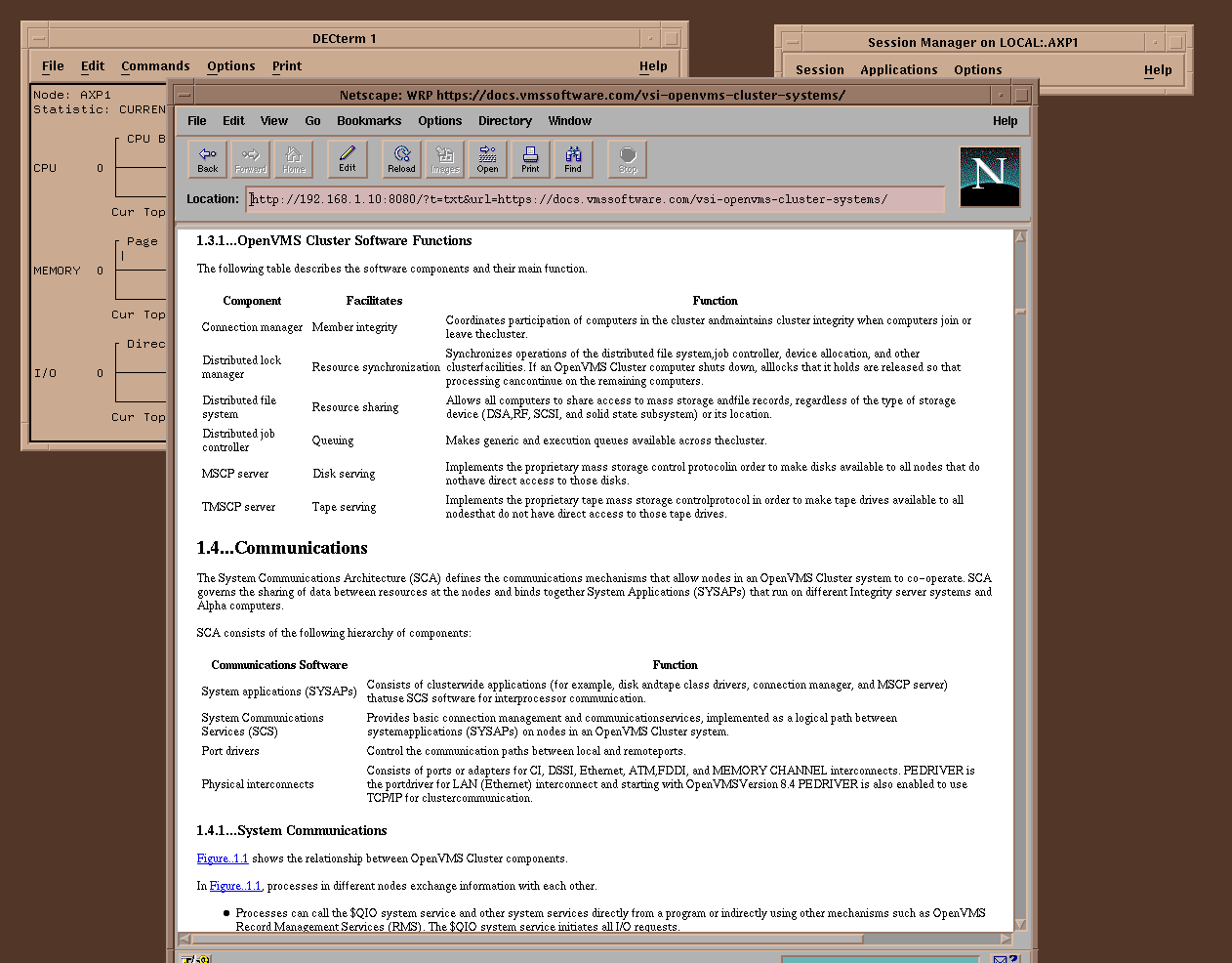
For the “mostly text” pages this is way better than screenshot mode. Not only is way faster and more responsive, you can select and copy text, but also you use the old web browser more like it was originally intended. At any time, if you want to view the screenshot mode, you can simply switch back to PNG/GIF/JPG mode with couple of clicks.
Another interesting aspect of this is extensibility and potential for improvement. For the screenshot mode there just isn’t that much stuff you could add. It’s just a screenshot. For Markdown and simple HTML there’s a million things one could add. Both down and up converters offer a wide variety of plugins and filters. We can improve formatting, layout, processing, add translation and other features. Perhaps also different features based on client browser version. Maybe even input forms and …images.
Lets talk about images. Right now they are completely deleted from markdown. This is for several reasons, compatibility, performance, load time, size, formatting, etc. I’m thinking that perhaps images could be added in some converted form. For example downsized to a small JPG or maybe converted in to ASCII art. Suggestions more than welcome!
Download from here: https://github.com/tenox7/wrp/releases/tag/4.7.0
To switch to Reader / Simple HTML mode simply change image type to “TXT”. This can also be done using -t txt flag.
Happy browsing!